경로 탐색 중 경로 탐색 알고리즘과 인접 행렬의 관계
많은 경로 탐색 코드는 인접 행렬을 생성한 뒤 경로 탐색을 수행합니다. 인접 행렬은 주변의 인접한 다른 노드와의 연결 상태를 표현할 수 있으므로 대부분의 상황에서 유용합니다.
인접 행렬의 사용
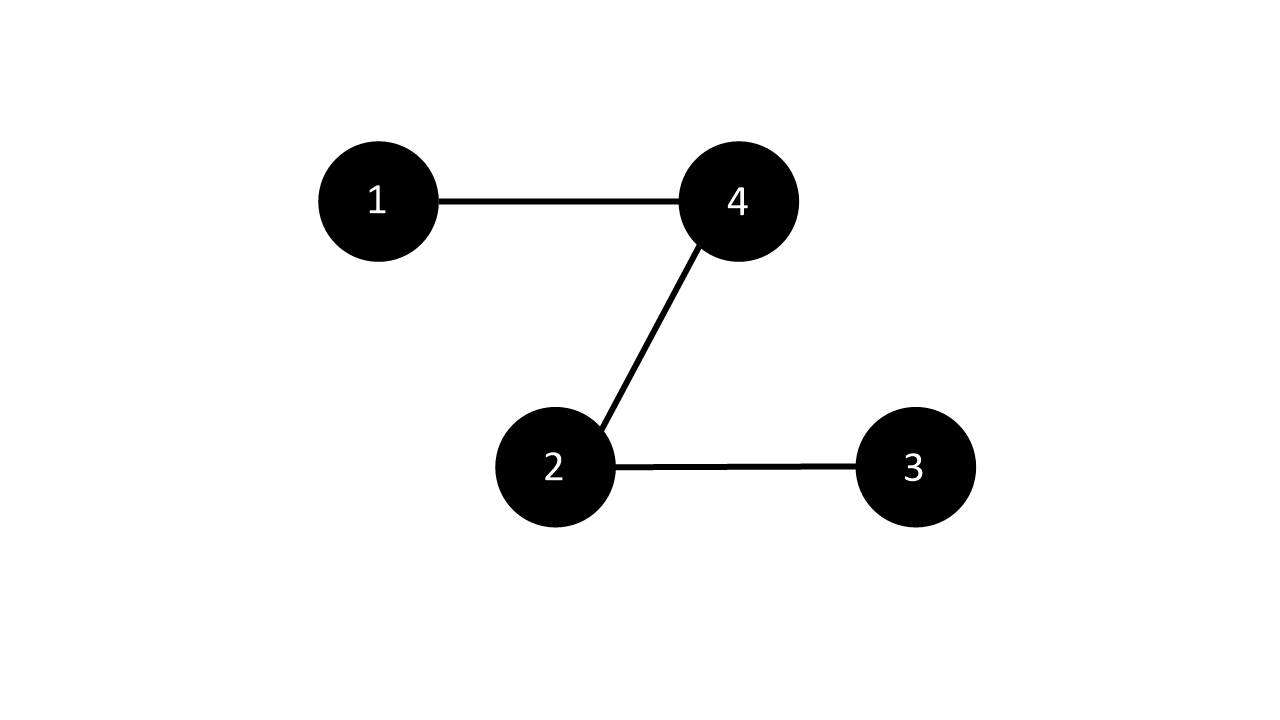
위와 같이 1번과 4번 점이 간선으로 연결되었다고 생각해봅시다. 가상의 인접 행렬 adj는 이렇게 정의할 수 있을 것입니다.
1
2
3
4
nodes = 5 # 노드의 개수 (0~4)
adj = [[False] * nodes] * nodes
adj[1][4] = True
adj[4][1] = True
경로 탐색 알고리즘은 이 인접 행렬을 유용하게 활용할 수 있고 결국 위 행렬을 통해 경로를 찾아낼 것입니다.
하지만 항상 인접 행렬이 필요한 것은 아닙니다. 입력으로 주어진 값의 형식에 따라 인접 행렬이 없어도 경로를 탐색할 수 있습니다.
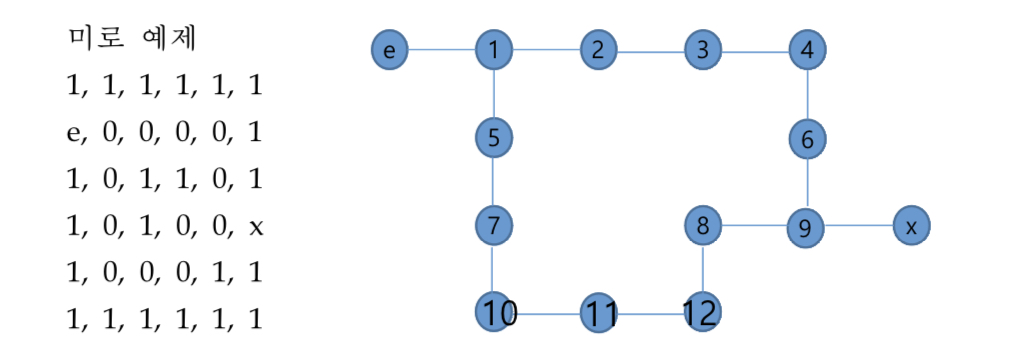
위 입력값에서 1은 벽, 0은 길이고 e에서 x로 진행하는 경로를 찾는다고 가정해봅시다.
앞서 제시된 그림과 달리 모든 점은 일정한 수준의 인접 노드가 존재합니다. 앞서 제시된 그림은 각 노드의 인접 노드가 간선으로 표현되어 인접 행렬을 통해 어떤 두 노드가 인접한지 확인해야 한다는 것입니다.
이 그림의 좌측과 같이 마치 그래프처럼 좌표계 상의 위치를 확인할 수 있는 입력은 인접한 점들을 확인할 수 있고, 그 점들로 이동할 수 있는지 여부를 판단하기만 하면 됩니다. 즉 좌측의 입력 값을 우측의 그래프로 변환하여 인접 행렬을 생성할 필요가 없습니다.
인접 행렬 생성 없이 경로 탐색
가장 널리 알려졌으면서 무난하게 사용할 수 있는 경로 탐색 알고리즘, BFS를 사용하여 경로를 탐색해봅시다.
1
2
3
4
5
6
7
8
9
10
11
12
13
...
def proc(self):
...
while self.queue:
now = self.queue.pop(0)
for dt in self.delta:
new: Pos = pos + dt
if self.pos_is_over(new): continue
if self.is_blocked(new): continue
if self.visited[new.y][new.x] == 0:
self.visited[new.y][new.x] = step
self.queue.append((new, step))
...
입력값이 좌표계 상 위치를 통해 특정될 수 있다면 인접 행렬 생성을 거치지 않는 것이 좋습니다. 위 코드와 같이 좌표를 사용하면 인접 점으로의 이동을 판단할 수 있습니다. 좌표계 상 위치가 주어지지 않아 인접 점의 정보를 기록해야하는 것이 아니므로 가능한 일입니다.
경로 탐색 중 인접 행렬 생성
하지만 인접 행렬을 꼭 생성해야 하는 경우라면 어떨까요? 대부분의 경우 인접 행렬은 목표 달성(=경로 탐색)의 수단일 뿐이지만, 이제 인접 행렬 자체가 목표가 되었습니다.
그렇다 하더라도 큰 문제는 없을지도 모릅니다. 경로 상의 모든 점은 탐색하게 되므로 탐색 과정에서 인접 행렬을 생성하는 처리를 추가하면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
...
def __init__(self, map: list):
...
self.adj = [[[[None for _i in range(self.height)] for _j in range(self.width)] for _k in range(self.height)] for _l in range(self.width)]
...
def proc(self):
...
while self.queue:
now = self.queue.pop(0)
for dt in self.delta:
new: Pos = pos + dt
if self.pos_is_over(new): continue
if self.is_blocked(new): continue
if self.visited[new.y][new.x] == 0:
self.visited[new.y][new.x] = step
self.adj[pos.x][pos.y][new.x][new.y] = True
self.adj[new.x][new.y][pos.x][pos.y] = True
self.queue.append((new, step))
...
하지만 여기 작은 문제가 몇가지 생겼습니다.
먼저 두 세칸 이상의 두꺼운 벽이 존재한다면 경로 탐색 알고리즘으로는 이 벽에 대한 인접 행렬을 생성할 수 없습니다.
입력
1
2
3
4
5
1 1 1 1 1 1
e 0 0 0 0 x
1 1 1 1 1 1
1 1 1 1 1 1
1 1 1 1 1 1
위 입력에서 ((1, 3) -> (2, 3)) 이동 가능 여부 확인하기
1
2
>>> solve.adj[1][3][2][3]
None
그래도 이 문제는 적절한 초기화를 통해 해결할 수 있습니다.
1
2
3
class Solve:
def __init__(self, map: list):
self.adj = [[[[False for _i in range(self.height)] for _j in range(self.width)] for _k in range(self.height)] for _l in range(self.width)]
1
2
>>> solve.adj[1][3][2][3]
False
그보다 큰 문제는 관심 있는 경로 바깥의 고립된 경로에 대해서는 인접 행렬을 생성할 수 없다는 것입니다. 뭐 그에 대한 자료가 필요한지는 둘째 치고 말입니다.
입력
1
2
3
4
5
1 1 1 1 1 1
e 0 0 0 0 x
1 1 1 1 1 1
1 0 0 0 0 1
1 1 1 1 1 1
위 입력에서 ((1, 3) -> (2, 3)) 이동 가능 여부 확인하기
1
2
>>> solve.adj[1][3][2][3]
False
인접 행렬 생성 후 경로 탐색
어떻게 탐색을 수행하든 경로 탐색 중에는 조명하고 있는 경로가 아닌 경로에 접근할 수 없습니다. 따라서 고립된 다른 경로에 대한 인접 행렬도 함께 생성하려면 경로 탐색 이전에 인접 행렬을 생성하는 수밖에 없습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Solve:
def __init__(self, map: list):
...
self.__init_adj()
...
def __init_adj(self):
for i in range(self.width):
for j in range(self.height):
...
for dt in self.delta:
new: Pos = now + dt
if self.pos_is_over(new): continue
if self.is_blocked(new): continue
self.adj[now.x][now.y][new.x][new.y] = True
self.adj[new.x][new.y][now.x][now.y] = True
...
입력
1
2
3
4
5
6
1 1 1 1 1 1
e 0 0 0 0 1
1 0 1 1 0 1
1 1 1 1 0 x
1 0 0 0 1 1
1 1 1 1 1 1
위 입력에서 ((1, 4) -> (2, 4)) 이동 가능 여부 확인하기
1
2
>>> solve.adj[1][4][2][4]
True
고차원 행렬의 좌표 압축
지금 다루고 있는 입력은 2차원 좌표계에 투영해서 처리하고 있습니다. 각 노드에게 임의의 2차원 좌표를 부여한 셈입니다. e 점은 (0, 1,), x점은 (5, 3)입니다.
인접 행렬은 시작점과 끝점의 정보를 활용합니다. 글의 도입부에서 1번 점과 4번 점에 대한 인접 행렬을 adj[1][4]로 표현했듯 말입니다.
2차원 좌표계에서는 각 점을 특정하는 값이 둘이므로 인접 행렬은 4차원 행렬입니다. 출발점 값 둘, 도착점 값 둘입니다. adj[a][b][c][d]로 표현할 수 있을 것입니다. a, b는 출발점의 (x, y), c, d는 도착점의 (x, y)입니다.
일반적으로 인접 행렬은 좌표계에 투영할 수 있는 노드에 대해 생성하지 않습니다. 1번 점, 2번 점, 3번 점…과 같이 좌표계에 노드의 위치를 투영하기 어려운 형식의 값을 사용하여 경로를 탐색하는데 활용됩니다.
이렇게 번호만 부여된 노드들을 1차원 좌표계 위에 투영한다고 생각하면 인접 행렬은 2차원 행렬입니다.
종합하자면 (1) 인접 행렬은 좌표계에 투영할 수 있는 노드에 대해 일반적으로 생성하지 않고 (2) 좌표계에 투영하기 어려운 형태의 입력값들은 1차원 값이라고 생각할 수 있으므로 (3) 인접행렬은 2차원 행렬이 가장 널리 알려진 형태입니다.
연장하자면 위에서 생성한 4차원 행렬은 흔하게 보기 힘든 형태라고 생각할 수 있습니다. 4차원 행렬을 2차원 행렬로 변환할 수 없을까요?
사실 다차원 배열이 컴퓨터 내부에선 1차원으로 처리되므로 비슷한 테크닉을 사용하여 2차원 좌표를 1차원 좌표로 압축할 수 있습니다.
1
2
3
for i in range(x):
for j in range(y):
i + j * x
2차원 좌표를 for문으로 처리하듯이 (열 + 열 너비 * 행)으로 변환하는 것입니다. (4, 4) 너비의 테이블에서 (1, 2)는 1 + 2 * 4 = 9로 변환됩니다. 이 방법은 조명할 좌표계 범위가 가변적이라면 사용할 수 없겠지만, 최소한 경로 탐색 도중에 좌표 범위가 변경될 일이 없으니 사용할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
...
def __init(self, map: list):
...
self.adj = [[False for _i in range(self.width * self.height)] for _j in range(self.width * self.height)]
...
def __init_adj(self):
for i in range(self.width):
for j in range(self.height):
...
now = Pos(i, j)
for dt in self.delta:
new: Pos = now + dt
...
self.adj[now.x + now.y * self.width][new.x + new.y * self.width] = True
self.adj[new.x + new.y * self.width][now.x + now.y * self.width] = True
...
위 입력에서 ((1, 4) -> (2, 4)) 이동 가능 여부 확인하기
1
2
>>> solve.adj[1 + 4 * 6][2 + 4 * 6] # 6은 열의 너비
True
노드에 임의 번호을 부여하고 경로 탐색하기
위와 같이 2차원 좌표를 1차원으로 압축하는 과정은 어떻게 보면 각 노드에 임의 규칙대로 번호를 부여한 것과 같습니다.
그렇다면 아예 처음부터 이동 가능한 좌표만 노드로 가정하고 노드에 임의로 번호를 부여하는 방식으로 접근할 수 있을 것입니다. 좌표계에 투영하기 용이한 데이터를 좌표계에 다소 투영하기 어려운 데이터로 변환하는 것입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
class Solve:
def __init__(self, map: list):
...
self.node_mapping = [[-1 for _i in range(self.height)] for _j in range(self.width)]
self.node_count = 1
self.__define_node_count()
self.adj = [[False for _i in range(self.node_count + 1)] for _j in range(self.node_count + 1)]
self.visited = [0 for _i in range(self.node_count + 1)]
self.dest_node = -1
self.__init_adj()
...
def __define_node_count(self):
'''
전체 노드의 개수를 구합니다.
'''
for i in range(self.width):
for j in range(self.height):
now = Pos(i, j)
if self.pos_is_over(now): continue
if self.is_blocked(now): continue
self.node_mapping[now.x][now.y] = self.node_count
if self.map[now.y][now.x] == X: self.dest_node = self.node_count
self.node_count += 1
def __init_adj(self):
'''
인접행렬을 초기화합니다.
'''
for i in range(self.width):
for j in range(self.height):
now = Pos(i, j)
node_now = self.node_mapping[now.x][now.y]
if node_now != -1:
for dt in self.delta:
new: Pos = now + dt
if self.pos_is_over(new): continue
if self.is_blocked(new): continue
node_new = self.node_mapping[new.x][new.y]
self.adj[node_now][node_new] = True
self.adj[node_new][node_now] = True
...
입력
1
2
3
4
5
6
1 1 1 1 1 1
e 0 0 0 0 1
1 0 1 1 0 1
1 0 1 0 0 x
1 0 0 0 1 1
1 1 1 1 1 1
위 입력에서 ((4, 2) -> (4, 3)) 이동 가능 여부 확인하기
1
2
3
4
5
6
>>> node_a = solve.node_mapping[4][2]
>>> node_b = solve.node_mapping[4][3]
>>> (node_a, node_b)
(12, 13)
>>> solve.adj[node_a][node_b]
True
제시한 전략들의 성능 측정
여러 알고리즘 이론이 “현실의 수학적 투영”보다 “작동 시간 최적화”을 위해 등장했을 정도로 구현체의 러닝 타임은 코드 작성에 있어 빼놓을 수 없는 중요한 고려 대상입니다. 위에서 제시한 여러 전략들을 다시 한번 분석해보며 얼마만큼의 러닝 타임이 필요한지 러프하게 확인해보겠습니다.
2차원 좌표계 투영
1
2
# proc
for dt in self.delta:
2차원 좌표계에 입력값을 투영하는 전략은 BFS만 구현하면 되므로 BFS 처리 시간만 집중하면 됩니다. 또, 하나의 처리 스텝마다 4회의 반복을 거칩니다.
인접 행렬 생성 후 2차원 좌표계 투영
1
2
3
4
5
# __init_adj
for i in range(self.width):
for j in range(self.height):
# proc
for dt in self.delta:
BFS 처리 시간은 앞서 살펴본 전략과 같이 처리 스텝마다 4회의 반복을 거치는 만큼 소모됩니다.
그에 더해, 경로 탐색에 앞서 인접 행렬을 생성하며 다시금 인접 좌표를 살피며 4회의 반복을 또 거칩니다.
앞서 살펴본 첫번째 전략이 경로를 탐색하며 인접 행렬을 생성했다면 이 전략은 반복문 내 인접 행렬 처리를 분리한 것이므로 이 전략과 첫번째 전략의 러닝 타임은 비슷할 것이라 생각할 수도 있습니다. 하지만 이 전략은 결과적으로 어떤 한 점에 대해 인접 점을 2회 확인하게 되므로 두 배 느리게 되었습니다.
노드에 임의 번호 부여하기(좌표계 투영 어려운 값으로 변환)
1
2
3
4
5
6
7
8
# __define_node_count
for i in range(self.width):
for j in range(self.height):
# __init_adj
for i in range(self.width):
for j in range(self.height):
# proc
for node_next in range(1, self.node_count + 1):
이 전략은 전적으로 임의로 생성된 인접 행렬에만 의존합니다. 인접 행렬을 생성하는데 들어가는 러닝 타임과 인접 행렬을 사용해 경로를 탐색하는데 들어가는 러닝타임이 이 전략의 러닝 타임입니다.
인접 행렬을 생성하는데 들어가는 시간은 직전의 전략과 비슷합니다.
하지만 경로를 탐색하는데 들어가는 시간은 인접행렬에만 의존해야 하므로 굉장히 오래 걸릴 수 있습니다. 매 BFS 스텝마다 번호가 부여된 모든 노드를 확인해야합니다. 다시말해 인접 좌표를 확인하는데 노드 수만큼의 반복이 필요합니다.
만약 번호가 부여된 노드의 수가 15개라면 인접 좌표를 확인하는데 매번 15회의 반복이 수행되어야 합니다.
결론
앞서 말했듯, 이 논의의 시작은 모 과목의 과제입니다.
이렇게 특별한 상황이 아니라면 경로 탐색 알고리즘 구현 시 2차원에 투영할 수 있는 값을 그대로 사용하지 않고 인접 리스트를 생성하는 것을 권하지 않습니다.
이미 쭉 살펴봤듯 불필요한 처리는 코드의 복잡성과 처리 속도를 증가시키는 짐이 될 뿐입니다.