Attention is All You Need 리뷰
RNN, LSTM, GRU와 같은 순환 모델들은 시계열 데이터를 다루면서, transduction 문제를 다루는 접근방식입니다. 동시에 많은 연구들이 encoder-decoder 모델의 도입과 같이, 이러한 모델들의 성능을 향상시키고자 노력하고 있습니다.
논문 발표 당시 최근의 연구에서 factorization tricks나 conditional computation와 같이 주목할만한 개선이 있었지만, 근본적인 문제가 해결된 것은 아닙니다.
어텐션 매커니즘은 입출력 시계열의 거리를 생각하지 않아도 되는, 설득력 있는 시계열 처리, 변환 모델이지만 순환 모델과는 잘 사용되지 않습니다.
그래서 연구팀은 순환을 피하고 어텐션 메커니즘만을 이용해 입출력 사이의 연관관계를 학습하는 트랜스포머 모델을 제안하게 되었습니다.
트랜스포머 모델의 구조
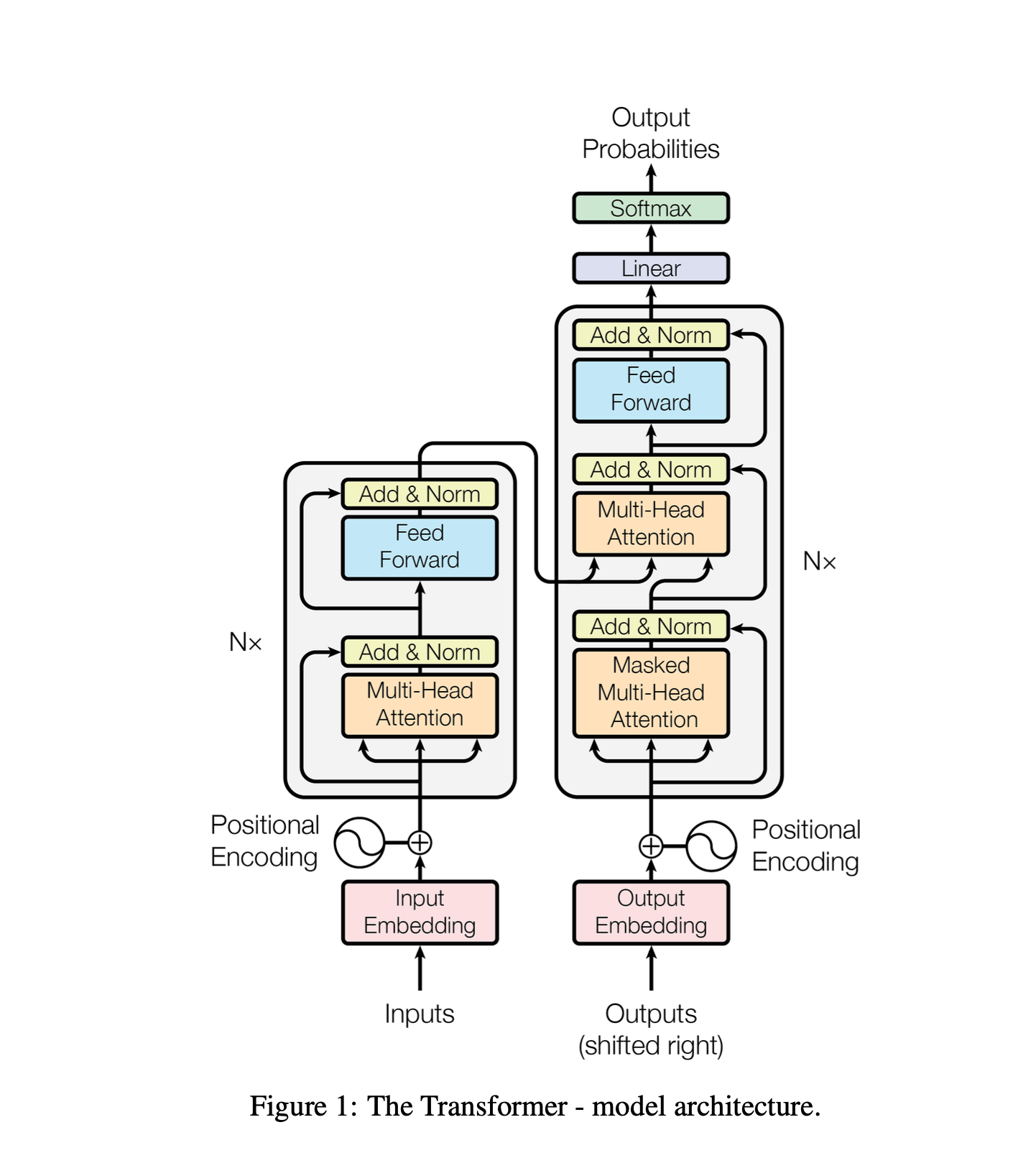
인코더와 디코더
인코더
인코더는 6개의 레이어로 구성되어있습니다.
각 레이어는 2개의 서브레이어로 구성됩니다.
첫번째 서브레이어는 multi-head self-attention 레이어이고, 두번째 서브레이어는 position-wise fully connected feed-forward network(ffnn)입니다.
\[\text{LayerNorm}(x + \text{Sublayer}(x))\]각 서브레이어 통과 후에 layer normalization을 수행하고 서브레이어 앞에서부터 잔차연결하여, 결과적으로는 위 수식과 같이 처리됩니다.
디코더
디코더도 6개의 레이어로 구성되나, 각 레이어가 3개의 서브레이어로 구성됩니다.
디코더는 인코더와 같이 multi-head self-attention 레이어, position-wise fc ffnn 레이어를 가지는데 더해, 인코더의 출력에 대해서도 multi-head attention을 수행하기 위해 추가적인 서브레이어를 가집니다.
동시에 인코더와 비슷하게 잔차 연결을 사용합니다.
다만 인코더의 multi-head attention 레이어는 디코더에서 변형되어 활용됩니다. 이것은 시계열 데이터가 한 번에 입력되기 때문에, 미래 시점의 값을 현재 시점에 참고하게 되는 상황을 방지하기 위함입니다.
Embedding
우선 모델에 데이터를 임베딩하여 입력합니다. 이 과정에서 임베딩된 벡터는 한번에 입력되므로 위치 정보가 포함되지 않습니다.
하지만 시계열 데이터를 처리하고 있으므로, 위치 정보를 함께 학습시키기 위해 임베딩된 벡터에 위치 정보 벡터를 더합니다.
\[V_{\text{Embedded}} + V_{\text{Position}} = V_{\text{Embedding with Sequence Position}}\]어텐션
Scaled Dot-product Attention으로 정의한 Self-Attention
이 연구에서는 Scaled Dot-Product Attention이라는 자체 정의한 어텐션 연산을 사용합니다.
이 어텐션은 셀프 어텐션*의 구현 방법 중 하나로, 셀프 어텐션이 그러하듯 문장에서의 단어들의 연관성을 평가하기 위해 사용합니다.
* The Illustrated Transformer의 저자, Jay Alammar는 이 논문을 접하기 전까지 셀프 어텐션이라는 개념을 알지 못했다고, 이 연구 이전에는 널리 쓰이는 용어가 아니었다고 설명하기도 합니다.
셀프 어텐션을 사용함으로서 순환 모델의 장기 기억 문제, 그래디언트 문제를 제어하고자 한 것으로 보입니다.
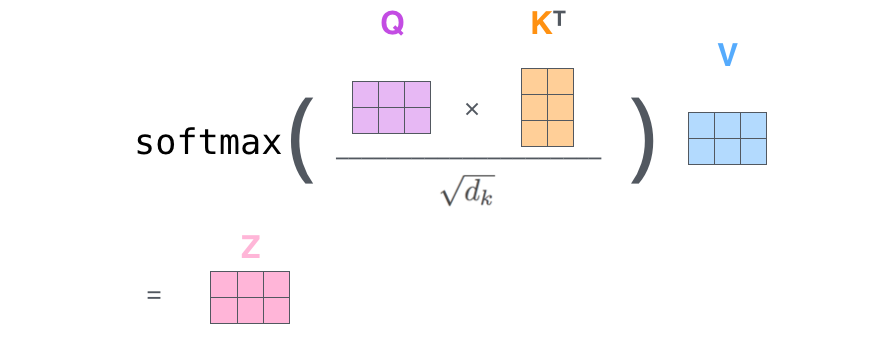
source: Jay Alammar, The Illustrated Transformer
Scaled Dot-product Attention에서는 계산하고자 하는 쿼리 벡터를 모든 키에 대해 내적 연산을 합니다. 내적 연산은 두 벡터가 유사할 수록 결과가 크므로 유사한 벡터를 찾을 수 있습니다.
이와 같이 내적 연산이 마무리되면 $\sqrt{d_k}$로 나눠서 정규화 처리한 후, 소프트맥스 함수를 취하고 값 벡터를 곱하여 출력을 획득합니다.
\[\text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\]Multi-Head Attention
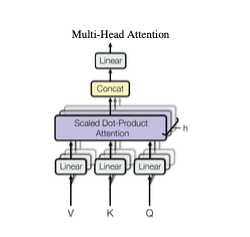
연구팀은 $d_{\text{model}}$ 차원의 키, 값, 쿼리 벡터로 single attention하는 것보다 $d_q(=d_k)$, $d_k$, $d_v$ 차원으로 키, 값, 쿼리를 투영하여 병렬로 어텐션 함수를 처리한 후 다시 concat하여 재투영하는 것이 더 좋다는 사실을 발견합니다.
\(\text{MultiHead}(Q, K, V) = \text{concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h)W^O\) \(\text{where} \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)\)
Multi-head attention은 다시 말해, 특정한 횟수만큼 (그림 상의 $h$) scaled dot-product attention을 수행하는 작업입니다.
Masked Multi-Head Attention
Masked Multi-Head Attention은 현재 시점 이후의 단어들을 치팅하지 못하도록, 뒤따르는 단어를 모두 비활성화하여 multi-head attention을 수행합니다.
\[\text{Scores} = \text{Query} \times \text{Keys}\] \[\begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{bmatrix} \Rightarrow \text{Apply Mask} \Rightarrow \begin{bmatrix} a_{11} & -\infty & -\infty \\ a_{21} & a_{22} & -\infty \\ a_{31} & a_{32} & a_{33} \end{bmatrix}\] \[\text{Softmax}( \begin{bmatrix} a_{11} & -\infty & -\infty \\ a_{21} & a_{22} & -\infty \\ a_{31} & a_{32} & a_{33} \end{bmatrix} ) = \begin{bmatrix} s_{11} & 0 & 0 \\ s_{21} & s_{22} & 0 \\ s_{31} & s_{32} & s_{33} \end{bmatrix}\]이 과정은 구체적으로는 현재 시점 이후의 단어들에 대해, 어텐션 스코어를 -inf 값으로 설정하여 소프트맥스 함수를 통과할 때 0에 수렴하도록 하는 방식을 채택으로 수행됩니다.
Between Encoder and Decoder
인코더 출력이 디코더 레이어에 전달되는 과정에서, 디코더는 인코더 출력의 키 벡터와 값 벡터만 받아옵니다. 쿼리 벡터는 masked multi-head attention의 출력을 활용합니다.
Position-wise Feed Forward
단순히 두 선형 변환 사이에 ReLU 활성화 함수를 취하는 Fully connected layer입니다.
\[\text{FFN}(x) = \text{max}(0, xW_1 + b_1) W_2 + b_2\]특기할만한 점은 이 레이어의 입출력은 512 차원이나, 중간 과정에서 2048차원까지 증가한다는 것입니다. ($W_1$: 512 to 2048, $W_2$: 2048 to 512)
Output
디코더의 출력은 linear layer와 softmax layer를 거쳐 가장 확률이 높은 단어를 출력으로 선택합니다.
마무리
트랜스포머 모델을 잘 알지 못해도 이 모델 자체가 너무 널리 알려져있고 “게임 체인저”로 평가되고 있기 때문에, 논문을 리뷰하기 전에는 트랜스포머 모델이 근본부터 다른 구조로 구성되어있지 않을까 기대했습니다. #1 #2
하지만 당연하게도 그러한 것은 아니었고, 트랜스포머 역시 인공지능 분야에 쌓여왔던 기성 연구들에 기반하여 등장한 것이었습니다. 물론 아직 인공지능에 식견이 부족한 것도 있겠지만 기대만큼 인상적이진 않았던 것 같습니다.
하지만 제 기대가 터무니없었던 것이고, 그 성능과 유용성은 이미 입증되어서 선술한대로 널리 사용되고 있습니다.