Deep Residual Learning for Image Recognition 리뷰
깊은 CNN의 등장이 이미지 분류에 있어 상당한 돌파구가 되어주었지만, 동시에 다양한 문제점을 가져다주었습니다.
은닉층이 깊어짐에 따라 그래디언트가 소실되거나 폭증하기 쉬워졌고, 높은 학습 오류율을 보였습니다.
특히 높은 학습 오류율은 과적합에 의해 발생한 것이 아니어서 적절한 수준을 넘어선 깊은 은닉층은 오히려 도움이 되지 않았습니다.
이러한 이유로 은닉층의 깊이가 깊어질수록 심층신경망은 학습시키기 더욱 어려워졌습니다.
마이크로소프트 팀은 이러한 문제를 해결하기 위해 잔차를 도입하게 되었습니다.
잔차 딥러닝
잔차 학습(Residual Learning)
여러 개의 비선형 레이어가 복잡한 함수를 근사할 수 있다고 가정해보겠습니다.
그렇다면 이 복잡한 함수의 각 부분을 여러 개의 레이어가 나눠서 학습하고 있는 것이므로, 첫번째 레이어를 지난 다음의 나머지 은닉층은 첫번째 은닉층이 근사한 수식의 나머지 부분을 근사하고 있을 것입니다.
복잡한 함수의 전체를 $H(x)$, 첫번째 레이어가 $x$를 근사했다고 가정한다면, 나머지 레이어는 $H(x) - x$를 근사하고 있을 것입니다.
하지만 중요한 점은 아무도 복잡한 함수의 전체 부분에서 어떤 부분을 각 레이어에게 학습해야 할지 지정하지 않았다는 점입니다.
그래서 각 은닉층이 전체로부터 일관된 부분을 학습할 수 있도 잔차 학습을 도입합니다.
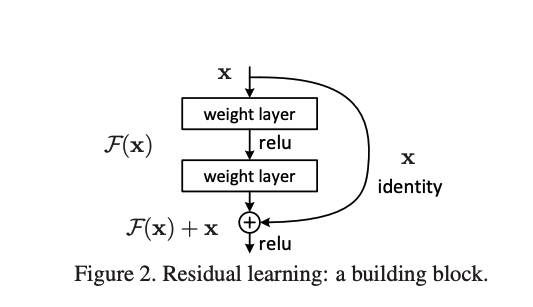
이렇게 쌓은 함수가 실제 학습시키고자 하는 복잡한 함수 $H(x)$와 완벽하게 일치하지 않을 수 있지만, 도움이 될 것이라고 주장합니다.
실제로 첨부된 실험 결과에서, 잔차 학습을 도입한 모델이 더욱 좋은 성능을 보여주었습니다.
항등 매핑(Identity Mapping)
하지만 이대로는 잔차 학습을 항상 도입할 수는 없습니다.
$ y = F(\text{x}, {W_i}) + \text{x} $
잔차 학습은 결국 각 레이어의 입출력을 더하면서 작동합니다. 입출력 차원이 서로 다른 레이어에 잔차 학습을 도입하는 것은 서로 다른 차원을 더하는 것과 같습니다.
따라서 입출력 차원이 서로 다른 레이어에 대해서, 입력이 표현하는 내용에 변화를 주지 않고 입력 차원을 출력 차원에 맞게 변환해주어야 할 필요가 있습니다.
$ y = F(\text{x}, {W_i}) + W_s \text{x} $
이 작업을 항등 매핑이라고 정의합니다.
입력 $\text{x}$를 출력값의 차원과 맞추기 위해 $W_s$에 linear projection합니다.
적용
네트워크 구조
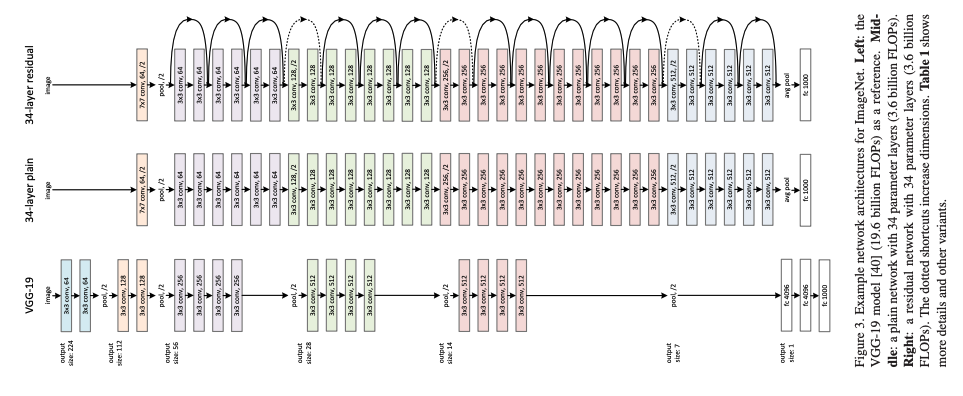
하단(좌측): VGG-19
중단(중간): VGG를 변형하였으나 잔차 학습을 적용하지 않은 모델
상단(우측): 중단(중간) 모델에 잔차 학습을 적용한 모델
연구팀은 VGG-19를 변형한 모델을 사용하여 잔차 학습을 실험했습니다.
우선 Plain Network를 두 규칙에 근거해 설계합니다:
- 출력의 feature map 크기가 같다면 같은 수의 필터를 사용한다.
- 출력의 feature map이 반감된다면 필터의 수를 두 배 늘려 레이어 별 시간복잡도를 유지한다.
여기에 더해, 다운샘플링은 stride가 2인 conv 레이어를 이용하고, 모델의 끝에 GAP(Global Average Pooling)과 소프트맥스를 적용한 크기 1,000의 FC 레이어를 추가합니다.
이어서 Residual Network는 Plain Network에 잔차 학습을 더하여 구현합니다.
입출력의 feature가 같은 레이어는 그대로 잔차 학습을 적용하지만, 입출력 feature가 같지 않은 경우 두 가지 방법을 사용했습니다.
- zero padding을 사용한다.
- 항등 매핑, projection shortcut을 사용한다.
구현
- 짧은 쪽이 $[256, 480]$이 되도록 임의로 샘플링
- 샘플링한 이미지를 그대로 사용하거나 horizontal fli하여 $224 \times 224$ 사이즈로 랜덤하게 크롭하여 샘플링
- Standard color augmentation 사용
- 각 컨볼루션에 활성화 함수 통과 직전, Batch normalization 사용
- Delving deep into rectifiers: Surpassing human-level performance on imagenet classification.과 같이 가중치 초기화
- 옵티마이저는 미니배치 크기 256으로 SGD 사용
- 학습률: $.1$; Weight decay: $.0001$; 모멘텀: $.9$
- 드롭아웃은 사용하지 않음
테스트 중에는 standard 10-crop 테스트를 적용했고, multiple scale을 사용해 이미지의 짧은 면이 ${224, 256, 384, 480, 640}$ 중 하나가 되도록 조정했습니다.
실험
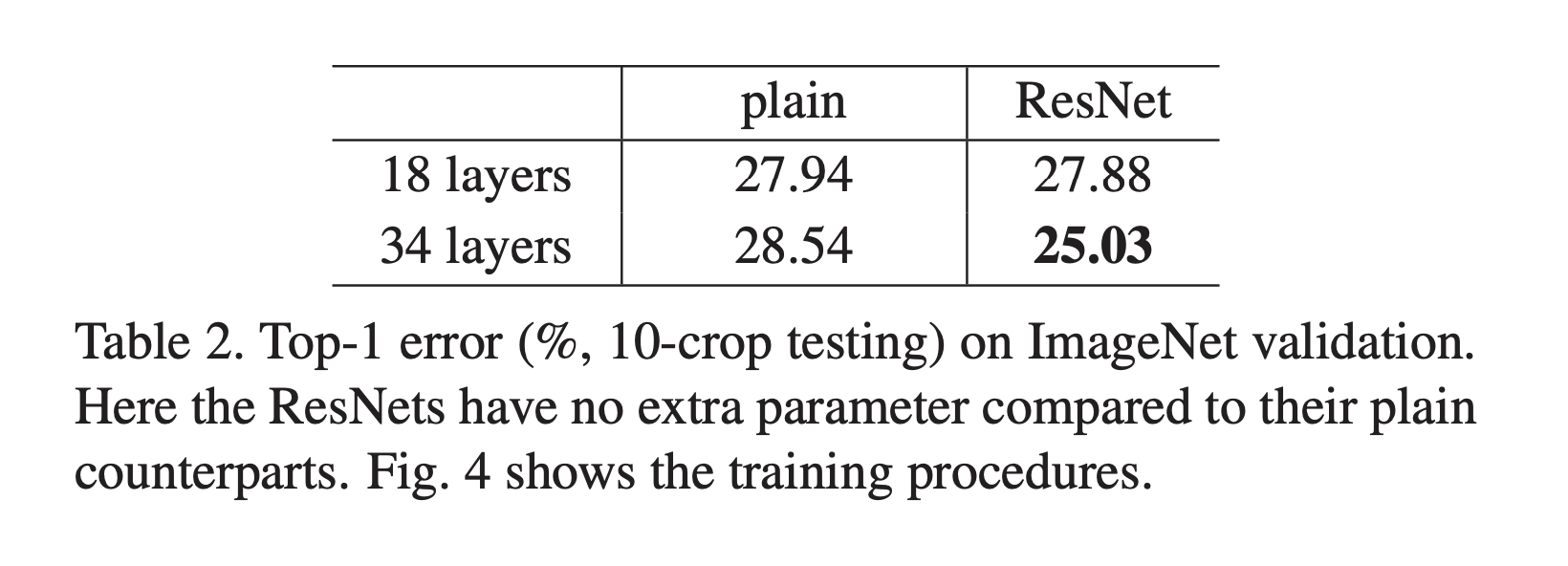
Plain network의 경우, 34-layer plain network가 18-layer plain network보다 오류율이 높음이 확인되었습니다.
하지만 순방향 전파 값의 분산이 0이 아니므로 이것이 그래디언트 소실로 발생한 것은 아닐 것이고, 실제로 역방향 전파에서 기울기도 healthy norm을 보였습니다.
연구팀은 이 plain network가 exponentially low convergence rate를 가졌기 때문에 이러한 현상이 발생했을 것이라고 추측했습니다.
Residual Network(ResNet)의 경우 모두 같은 깊이의 신경망에서 성능 개선이 있었고, 특히 34-layer ResNet은 18-layer ResNet보다 높은 수준의 개선을 보였습니다.
18-layer plain network와 ResNet은 성능이 유사하지만, 18-layer ResNet이 더 빠르게 수렴했습니다.
다시 말해 모델이 깊지 않아도 ResNet이 더 빨리 수렴하므로 여전히 plain net보다 우위에 있습니다.
변형 ResNet

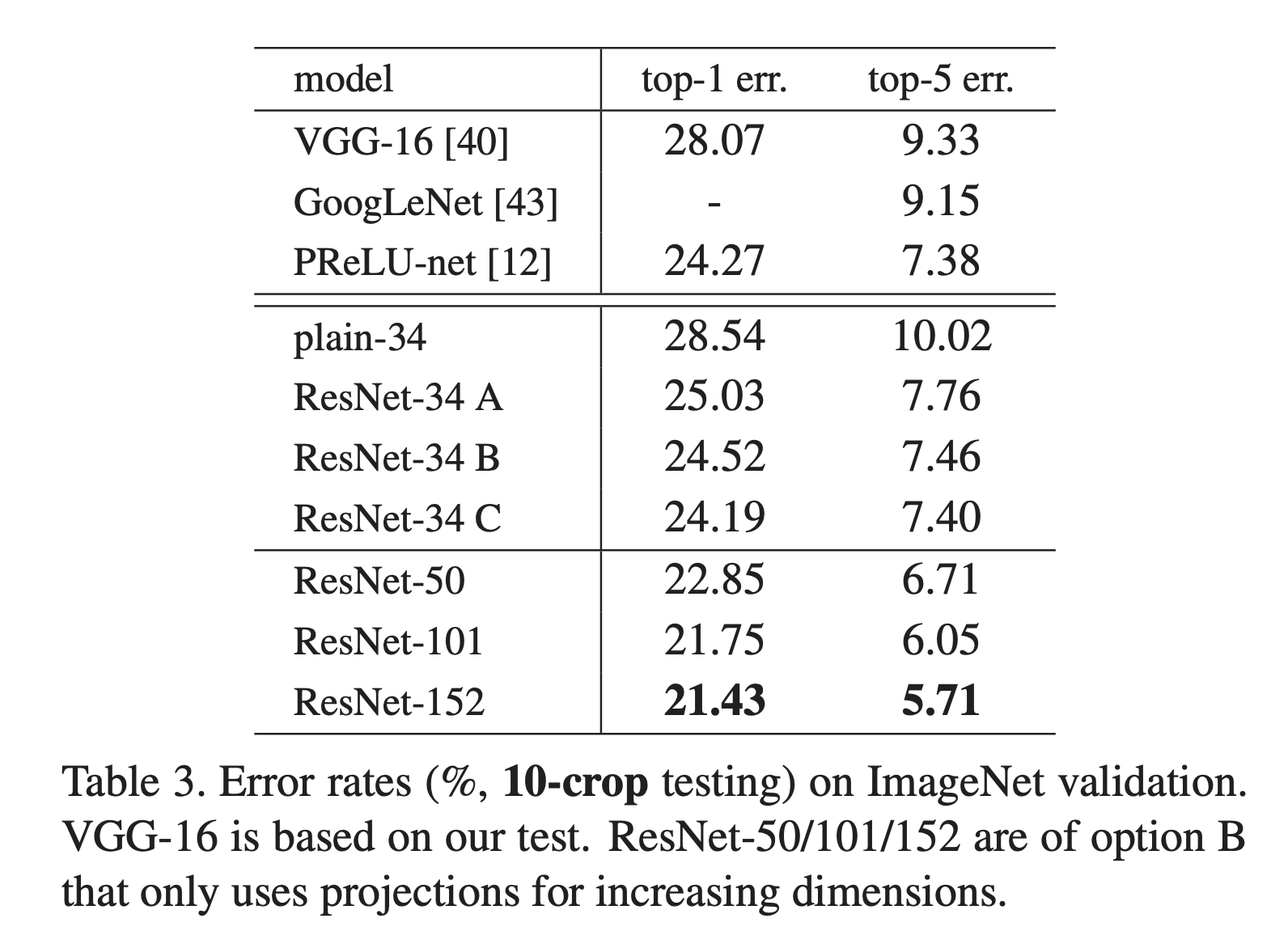
Shortcut
또 shortcut에 대해서도 세 가지 방법을 두고 비교했습니다.
A. 차원 조정 시에만 zero-padding shortcut을 사용
B. 차원 조정 시에만 projection shortuct을 사용
C. 모든 shortcut에 project shortcut을 사용
* Table 3.의 <ResNet-34 [A|B|C]> 참조
세 방법 모두 C, B, A 순으로 plain model보다 좋은 성능을 보였습니다.
A의 경우 zero-padded 차원이 residual learning을 수행하지 않기 때문에, C의 경우 project shortcut에 의해 파라미터가 추가되어서 성능 차이가 발생했습니다.
세 방법의 성능 차이가 크지 않았기 때문에, projection shortcut이 degradation 문제를 다루는데 필수적이지 않았습니다.
따라서 메모리 복잡도와 시간 복잡도, 모델 크기를 줄이기 위해 3. 방법은 사용하지 않았습니다.
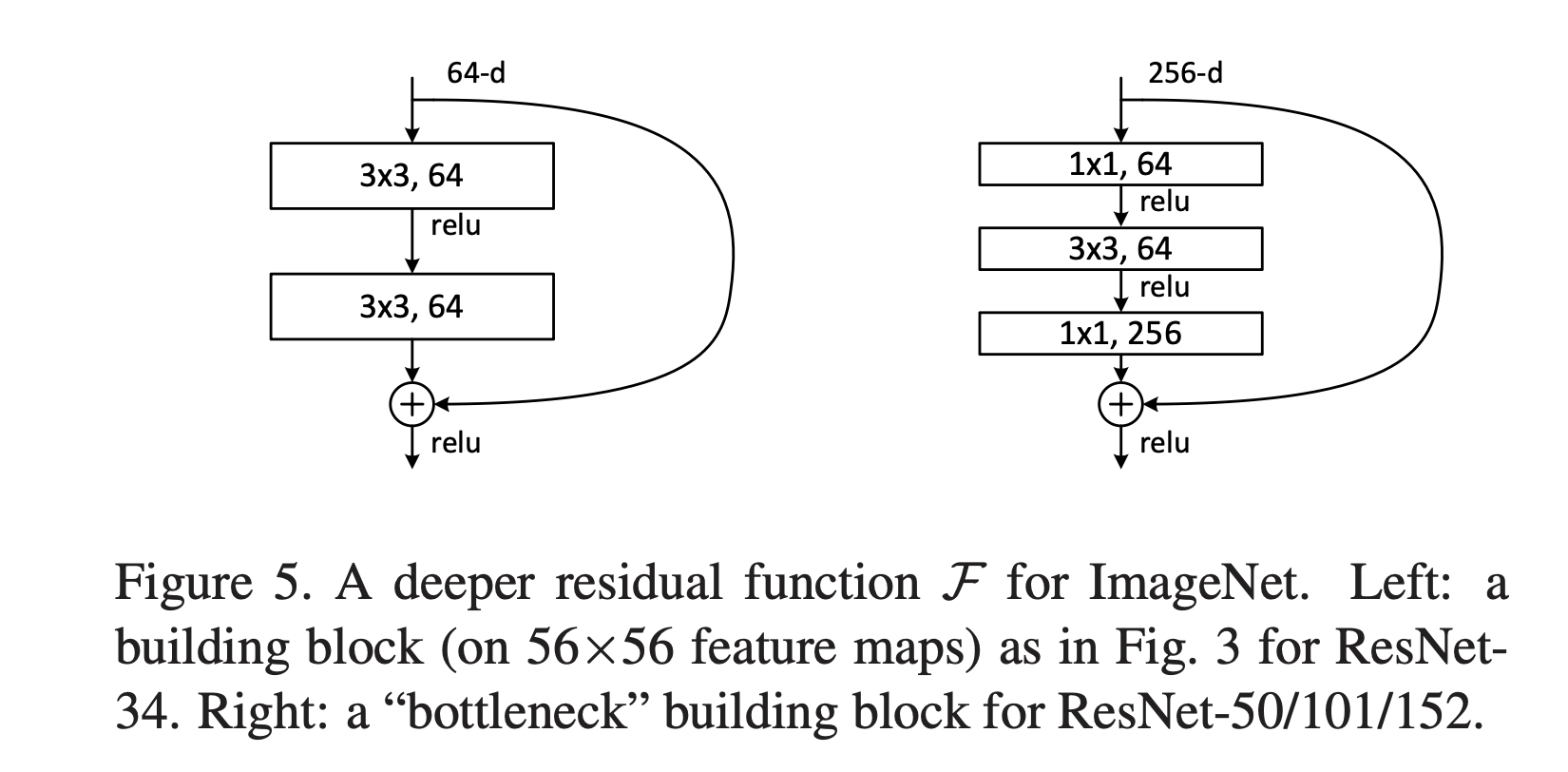
Bottleneck Design Block
그 외에도 학습 시간에 우려가 있었기 때문에, 블록을 병목 디자인으로 수정했습니다.
만약 이 상황에서 shortcut이 identity shortcut이 아니라 projection shortcut이 사용된다면, shortcut이 2개의 고차원 출력과 연결되어서 시간복잡도와 모델 크기가 두 배로 늘어납니다.
따라서 이 디자인에서는 identity shortcut을 사용했습니다.
연구팀은 ResNet에 Bottleneck 디자인을 적용하여 더 깊은 신경망을 만들었습니다.
- 50-layer ResNet: <Figure 6> 34-layer ResNet의 2-layer 블록을 3-layer bottleneck 블록으로 변경
- 101-layer ResNet: <Table 1> Bottleneck layer 일부를 더 깊게 수정
conv4_x: 6 $\Rightarrow$ 23
- 152-layer ResNet: <Table 1> Bottleneck layer 일부를 더 깊게 수정
conv3_x: 4 $\Rightarrow$ 8conv4_x: 6 $\Rightarrow$ 36
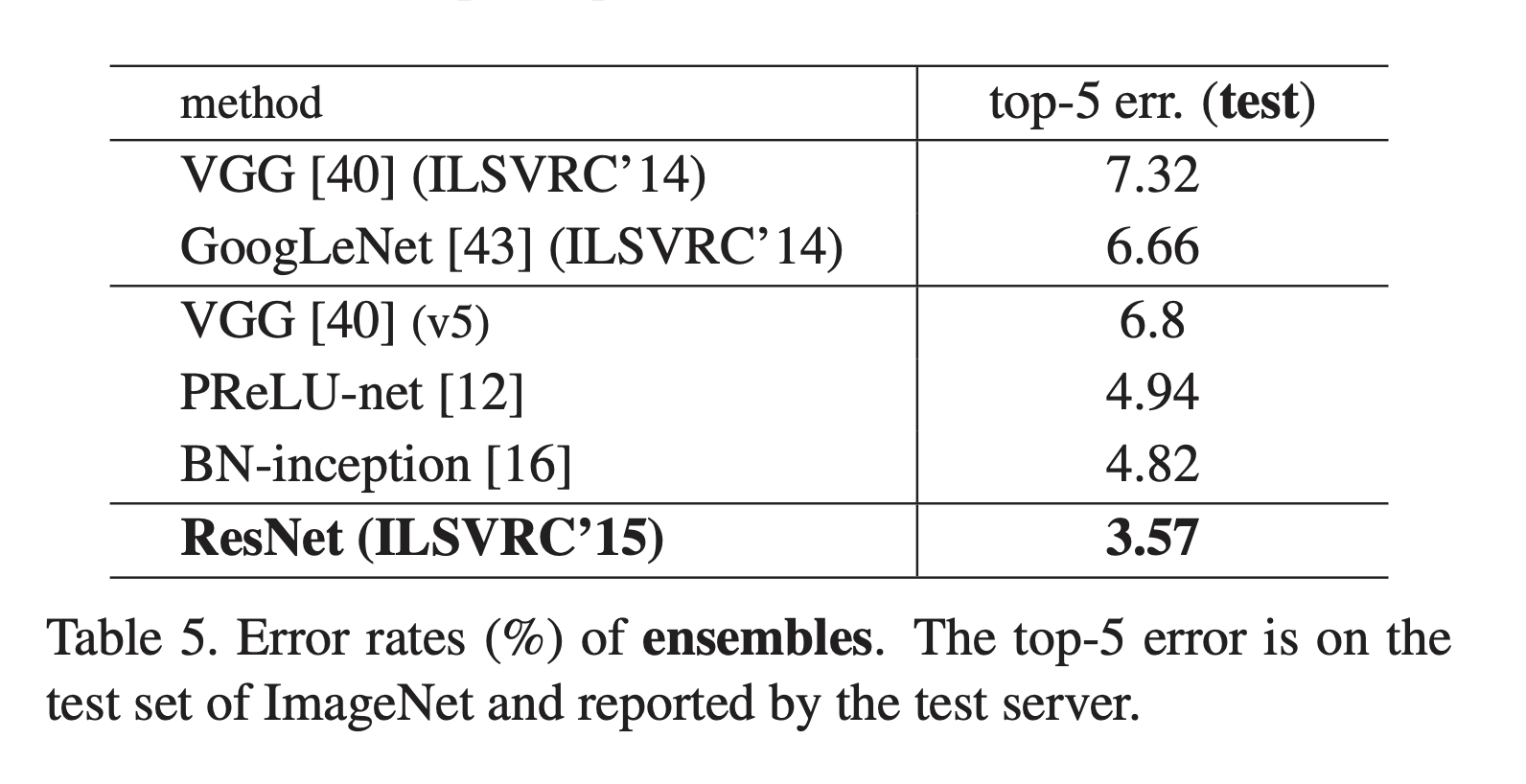
또 ResNet은 앙상블을 적용하지 않아도 앙상블이 적용된 다른 모델보다 성능이 좋았는데, 앙상블을 적용하니 top-5 error가 3.57%까지 내려가는 결과를 달성했습니다.
Layer Responses
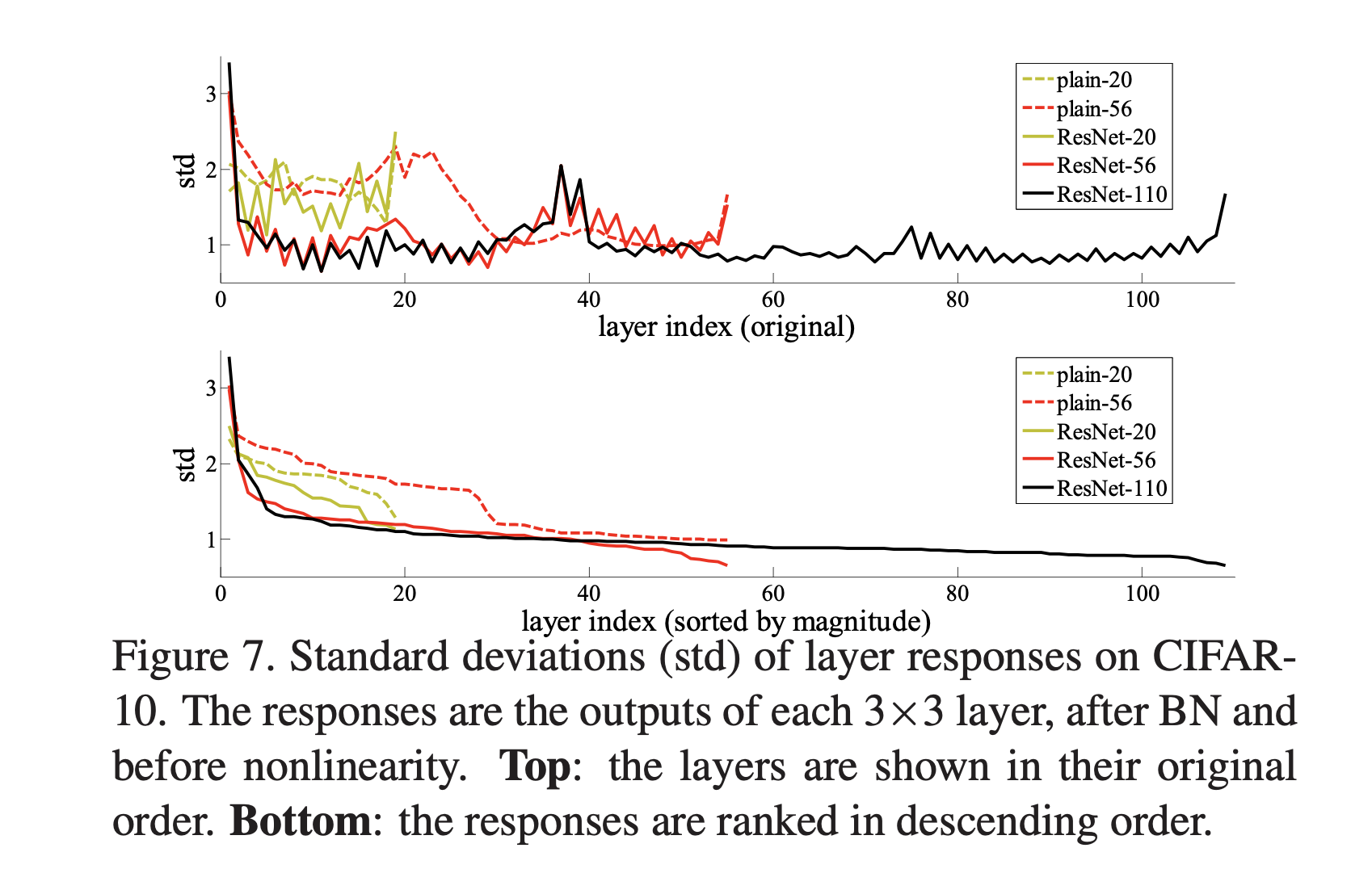
ResNet의 response는 plain net보다 낮게 나타났습니다.
이는 residual function이 non-residual function보다 0에 가까울 것이라는 주장의 근거가 됩니다.
Over 1000 Layers
ResNet이 최적화에 어려움이 없는 것으로 보였기 때문에 1000층이 넘는 모델도 실험해보았습니다.
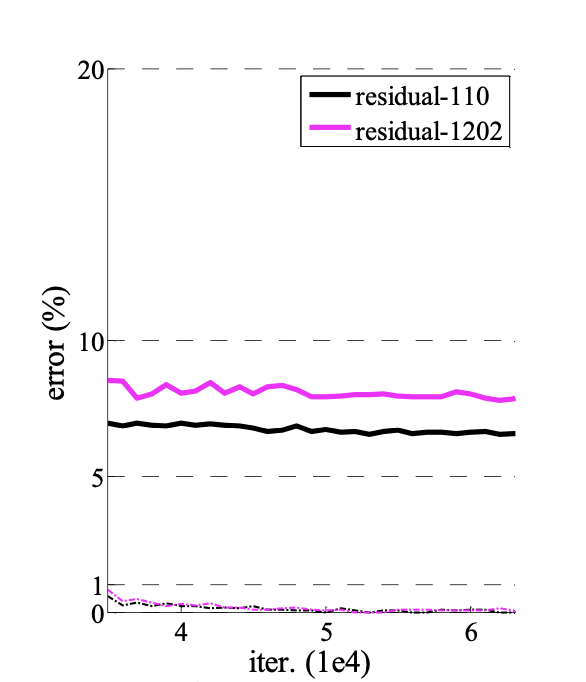
Figure 6 (Right)
- 1000-layer network: 0.1% 이하의 training error를 달성했고, test error가 7.93%로 괜찮은 수준으로 나타났습니다.
- 1202-layer network: 여전히 training error는 낮으나 110-layer network보다 더 높은 오류율을 보여, 오버피팅된 것으로 평가됩니다.
PASCAL과 COCO에 적용하기
연구팀은 물체 인식 처리를 101-layer ResNet(ResNet-101)을 PASCAL와 COCO 데이터셋으로 학습시켰고, ILSVRC & COCO 2015에서 우승했다고 합니다.
마무리
학부 인공지능 수업에서 잔차 연결이나 ResNet을 제대로 배우지 못했기 때문에, 잔차 연결이라는 표현을 보고도 그 내용을 제대로 이해하지 못했습니다.
그래서 잔차 연결이라는 표현이 나왔을 때 추가적으로 더 조사를 해야 했고, 그럼에도 불구하고 어째서 잔차 연결이 효과를 보이는지 잘 이해하지 못했습니다.
잔차 연결이 등장한 배경, ResNet 등장 이전에 연구자들이 당면한 다양한 문제, 특히 그래디언트 문제들을 해결하는데, ResNet이 상당한 역할을 했음을 잘 이해하게 된 것 같습니다.
ResNet이 당대의 연구 사이에서 상당한 향상을 견인하였고, 연구 발표 당시의 모델에서 괄목할만한 성과를 달성했다는 점도 인상깊은 것 같습니다.