보이스 끄투: 끝말잇기 게임에 STT 도입하기
GitHub Repository: embedded-voice-kkutu
이번 학기에 수강한 <임베디드소프트웨어>는 중간고사에 이어 기말고사도 프로젝트로 대체하여, 한 학기에 총 2회의 프로젝트를 수행해야합니다.
중간고사 기간의 프로젝트가 단순히 아두이노 기판을 사용하는 것이 목표였다면, 기말고사 기간의 프로젝트는 AI 모델을 최적화하여 임베디드 환경 대응 AI 소프트웨어를 작성하여 라즈베리파이 4 B+ 보드 위에 올리는 것이 목표가 되었습니다. 특히 양자화 처리를 중시하는 것 같았으므로, AI 모델 적용 과정에서 이 부분에 신경쓰기로 했습니다.
우리 팀은 끝말잇기에 음성 입출력, 다시 말해 STT와 TTS 모듈을 붙이는 것을 목표로 잡았습니다. 주제가 주제이다보니 끄투를 꽤 참고하게 되었습니다.
그 외에 저번 지스타 컨퍼런스에서 접하게 된 게임 <마법소녀 카와이 러블리 즈큥도큥 바큥부큥 루루핑>과 발표 <AI 시대의 이차원 게임 개발>에서의 넥슨의 AI 도입 검토 과정도 주제를 잡는데 도움이 되었습니다.
해커톤 소프트웨어 프로젝트

팀원 모두가 동 학기 교육과정의 캡스톤 디자인에 더 집중하느라, 실질적으로 프로젝트를 시작한 것은 캡스톤 디자인이 마무리되고 임베디드 과목도 마감을 얼마 남기지 않은 시점이었습니다. 따라서 마감에 맞춰 자체적으로 단어 DB를 구축하는 것도 어려웠고, STT나 TTS 모델의 구축도 마찬가지로 어려웠습니다. 사실 학부 단계에서 학기 내에 적절한 성능의 STT 모델이나 TTS 모델을 자체적으로 만들어내는 것은 비현실적인 일일지도 모릅니다.
끄투 리포지토리에서 단어 데이터 마이그레이션하기
다행히 끄투 레포에서는 충분한 양의 단어 데이터를 포함하고 있었습니다. 이전에 단어 사전 저작권 관련해서 설왕설래가 조금 있었던 것으로 기억하는데, 다른 개발자의 문제이거나 이미 해결된 문제인 것 같습니다. 그래서 끄투의 단어 데이터를 우리 프로젝트에 마이그레이션하도록 했습니다.
끄투 레포에 GPL 3.0이 적용되어있었으므로 끄투 단어 데이터도 GPL 3.0을 기준으로 끌어왔습니다. 사실 구체적인 유권해석을 할 여유가 없어서, 프로젝트 레포에는 끄투를 제외시키고 별개 유틸로 끄투를 끌어와 마이그레이션하도록 했습니다. 이렇게 레포에서 끄투 자체를 제외하기는 했으나, 실제로는 끄투를 서브모듈로 지정해두었으므로 역시 유권해석을 할 여유가 없어 프로젝트에도 GPL 3.0을 적용시켰습니다.
단어 데이터에는 단어의 뜻이나 출처, 내부 제어 플래그 같은 것들이 함께 존재했지만 사용하지는 않았습니다. 디스플레이 입출력은 고려 대상이 아니었고, 뜻을 제외하고 단어만 TTS로 읽는 것도 충분히 오랜 시간이 걸렸습니다. 끄투 게임 엔진 코드를 재사용할 것도 아니었으므로 단어 목록 외에는 모두 제거해도 됐습니다.
STT 모델 선정
앞서 언급했듯 마감까지 며칠 남짓한 시점에서 학부생이서 STT 모델을 새로 만들어내는 것은 무리입니다. 사실 그 누구든 며칠 안에 새 STT 모델을 짜내는 것은 무리일 것입니다. 그래서 이미 존재하는 모델과 API를 가져와 사용하기로 했습니다.
최초에는 VOSK의 도입을 검토하였습니다. 많은 라즈베리파이 온보드 STT 사례가 VOSK를 구현체로 삼아서 자료가 풍부한데다 한국어를 지원하는 모델이기 때문입니다. 하지만 실험 결과 한국어 음성 인식률이 전반적으로 좋지 않았습니다. 단순히 띄어쓰기를 잘못하거나 하는 문제라면 적절히 후처리해서 사용할 수 있겠지만, 그냥 발음 인식 성능이 좋지 않았습니다.
이어서는 Whisper 모델의 도입을 검토하였습니다. VOSK보다 한국어 인식 성능이 더 뛰어났지만 더 많은 성능을 요구했습니다. 기한 내에 모델을 분석하면서 직접적인 최적화를 도모하는 것은 어려웠지만, 파라미터 개수가 조정되어 성능 요구치가 낮은 모델tiny도 있었으므로 이것을 사용하기로 했습니다.
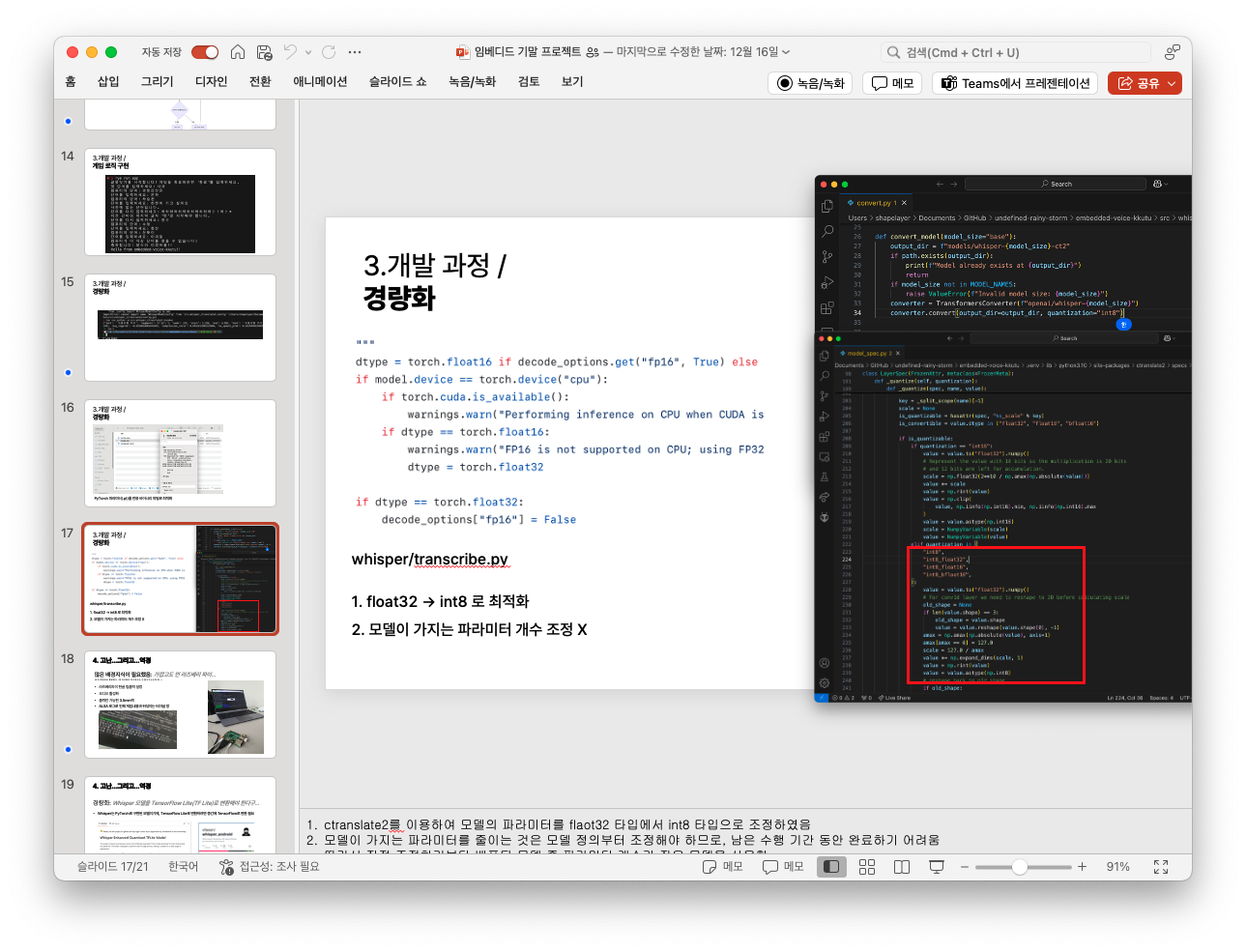
이어서 프로젝트의 핵심 요구 사항이기도 한 양자화 처리를 적용했습니다. 양자화 처리는 프로젝트 수행 발표 24시간을 남짓한 시기에 시작하였으므로 직접 양자화 코드를 짜는 것은 사실 말이 안되었고, ctranslate2를 사용하여 8비트 정수로 양자화하여 전용 바이너리로 마이그레이션했습니다.
배포중인 모델이 이미 양자화되어있는지는 제대로 확인하지 않았으나, 코드로 보나 논문으로 보나 8비트 자료형으로의 양자화는 적용하지 않은 것 같았습니다.
입력 제어하기
\[f_\text{RMS} = \sqrt{\frac{1}{1024} \int^{T + 1024}_{T} [f(t)]^2} {\rm d}t\]STT 모듈에 실시간으로 음성 입력을 넣기 위해서 발화 시점부터 종점까지의 음성 샘플을 버퍼링하여 사용하도록 하였습니다. 최근 1024 프레임의 샘플에 대해 RMS를 구해 역치를 넘어가는 구간을 선택하는 방식으로 구현하였습니다.
사실 장치마다 수음 능력이 상이하였기 때문에 역치 값을 일일이 조정해야했습니다. 역치를 조정하는 코드를 작성하는 것보다 장치별로 수동으로 역치 값을 찾아내고 관리하는 것이 더 현실적이었습니다.
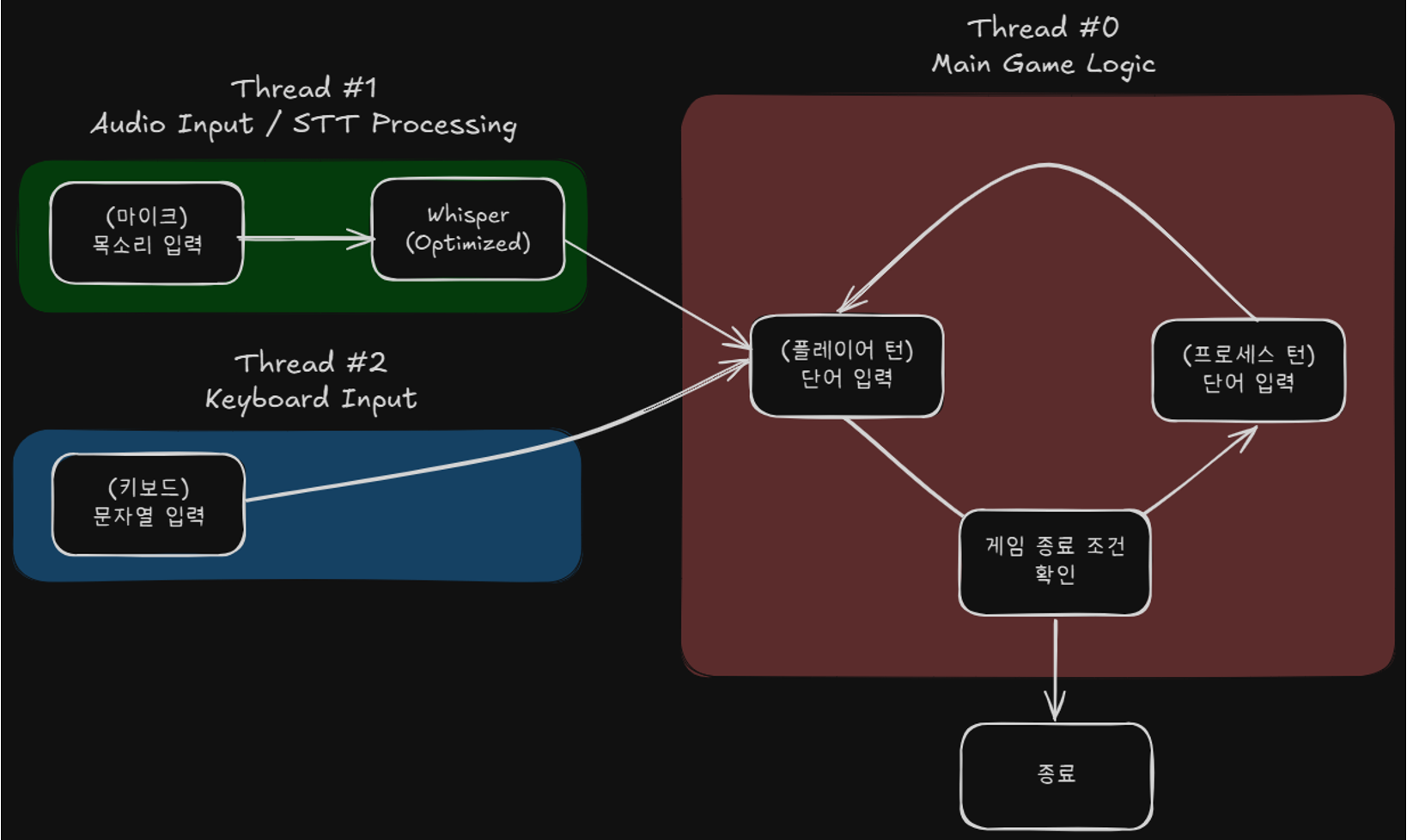
음성 입력은 마이크 입력, 역치 계산, STT 모델 처리를 거쳐야 제대로 동작할 수 있었습니다. 그래서 음성 모듈 오작동 대책으로 표준입력과 음성 입력 모듈을 병렬 동작시켰습니다.
TTS 적용하기
STT에 많은 시간을 투자하게 되면서 TTS는 gTTS를, 즉 구글 번역기의 TTS 기능을 사용하기로 했습니다. 하지만 프로젝트 발표 시기에서는 프로젝트에서 제외되었습니다. TTS 기능을 처리할 모듈은 만들었으나, 모듈 제어 코드를 메인 게임 흐름에 적용하지 않았다는 사실을 너무 늦게 깨달았습니다.
발표
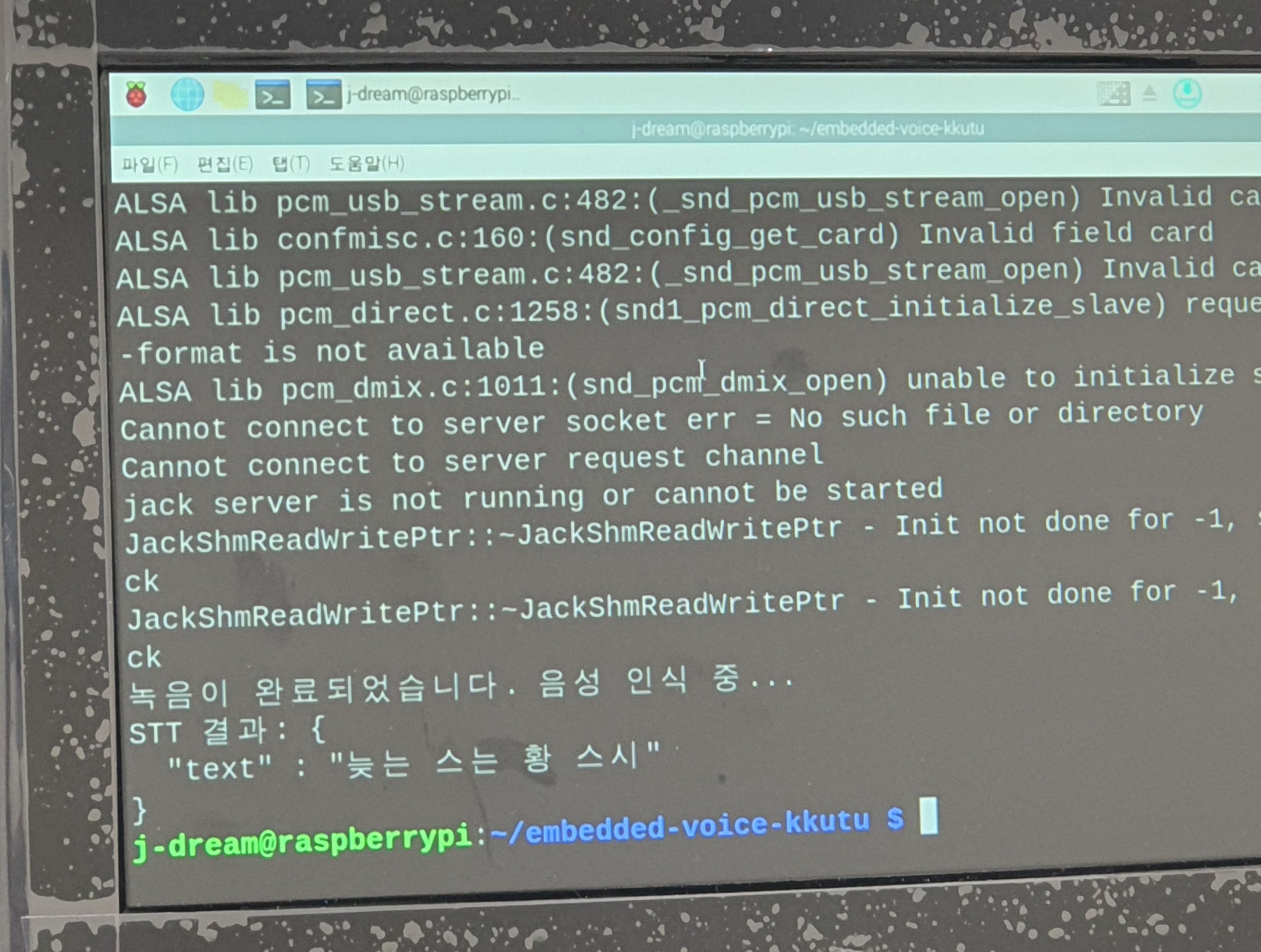
발표 수 시간 전에 라즈베리 환경에서 PyAudio의 ALSA 호환 문제를 발견했습니다. ALSA를 제대로 로드하지 못하는 것처럼 보였습니다. 드라이버를 조정하거나 OS를 재설치하기도 했는데도 해결되지 않았습니다.
정말로 다른 환경에서 재현되는지도 확인할 여유도, 원인을 더 찾을 여유도 없어서 PyAudio 의존성을 SoundDevice로 마이그레이션시켰습니다. 남은 시간 동안 만들어내야하는 발표자료는 전적으로 팀원에게 의지했습니다.
발표에 사용한 최종 릴리즈는 발표를 10분쯤 앞두고 뽑아냈습니다. 정말 아슬아슬한 시점에 마무리를 했습니다. 하지만 시연은 실패했습니다. 음성 입력이 제대로 수행되지 않았습니다.
원인은 두 가지였습니다. *USB 포트가 불량하여 OS 자체에 음성 입력이 들어가지 않는 문제를 음성 입력 장치가 고장나서 발생한 것으로 잘못 분석한 것. *수동으로 설정한 역치 값이 잘못된 값으로 설정된 것.
둘 다 마감까지의 여유가 없다는 이유로 평소에는 하지 않았을 행동을 한 것이 문제가 되었습니다. 이후에 교수님께서 시연 실패를 만회할 수 있도록 따로 시연 영상과 보고서를 제출하도록 배려해주시지 않았다면 정말 어려운 상황이었을텐데 다행입니다.
그래도 현장에서 성공했으면 더 괜찮은 평가를 받을 수 있을텐데 아쉽습니다.