t-분포와 t-검정
〈빅데이터의과학적탐구〉 수업 노트
정규분포를 따르는 어떤 모집단에서 표본을 추출할 때, 모집단이 정규분포를 따르므로 표본도 정규분포를 따를 것이라는 기대를 할 수 있다. 그러나 표본이 충분히 크지 않다면, 표본집단은 모집단의 성격을 왜곡할 수 있는 가능성이 있다. 표본이 작으면 작을 수록, 모집단을 표본이 제대로 표현하지 못하는 것이다.
작은 크기의 표본을 여러 개 추출하여 이들의 분포를 그래프로 그리면, 정규분포 그래프보다는 조금 더 퍼져있는 그래프를 확인할 수 있다. 표본의 크기가 작을 수록, 표본은 모집단을 더욱 대표하지 못하고, 그래프는 더 퍼진다. 반대로 표본의 크기가 커질수록, 표본은 모집단을 더 잘 대표하게 되고, 그래프는 정규분포에 가까워진다.
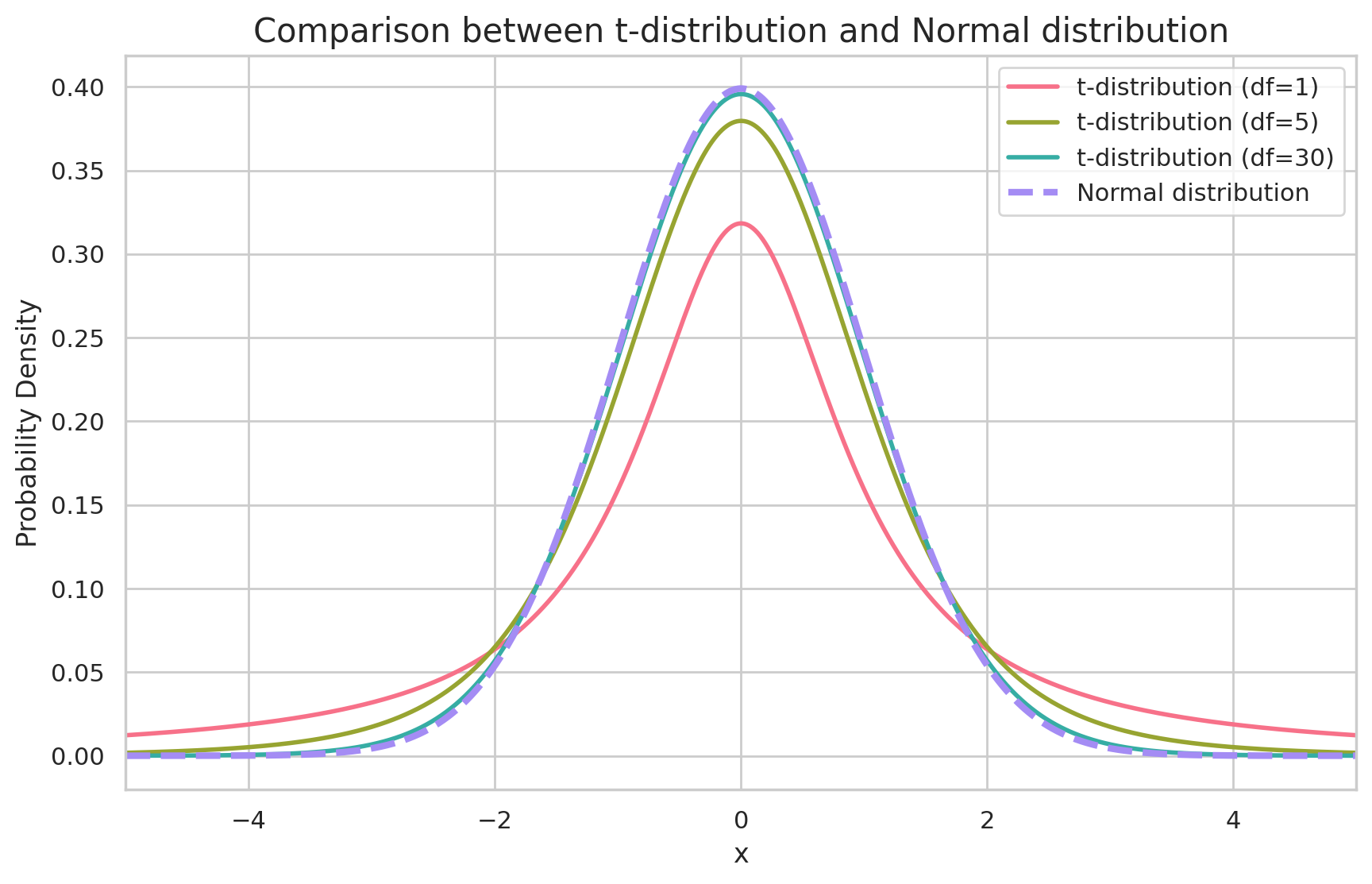
이렇게 표본의 크기에 따라 그래프의 모양이 달라지는 분포를 t-분포라고 한다.
t-분포의 정의
t-분포는 확률변수 $X$ 와 자유도가 $k$ 인 카이제곱분포 확률변수 $Y$ 에 대해 다음과 같이, 혹은 $N(0, 1)$ 을 따르는 $Z$, $\chi^2_v$ 를 따르는 $U$ 를 사용하여 정의한다.
\[\begin{aligned} T &= \frac{X}{\sqrt{Y/k}} \\ &= \frac{Z}{\sqrt{U/v}} \sim t_v \end{aligned}\]모집단이 $N(0, 1)$ 을 따르므로, $E(T)=0 (v>1)$ 표준정규분포와 평균은 같으나, $Var(T)=\frac{v}{v-2} (v>2)$ 로, 분산은 t-분포가 항상 더 크다.(표본의 크기가 $\inf$ 로 발산한다면 이미 모집단이라고 가정할 수 있을 것이므로, 표준정규분포의 분산과 같아질지도 모르겠으나, 그건 이미 표본이 아니다.)
$Z$ 와 $U$ 가 아래와 같을 때, t-분포는 아래와 같이 표현한다. 표본평균 $\overline{X}$ 의 표준화 식에서 모표준편차 $\sigma$ 를 $s$ 로 대체한 식이 t-분포라는 것을 알 수 있다.
\[\begin{aligned} Z = \dfrac{\overline{X} - \mu}{\sigma/\sqrt{n}} \sim N(0,\ 1) \\ U = \dfrac{(n - 1)s^2}{\sigma^2} \sim \chi^2_{n - 1} \end{aligned}\] \[\begin{aligned} T &= \dfrac{Z}{\sqrt{U/v}}\sim t_v \\ &=\dfrac{\cfrac{\overline X - \mu}{\sigma/\sqrt{n} }}{\sqrt{\cfrac{(n-1)s^2}{\sigma^2}/(n-1)}} \\ &=\dfrac{\overline X-\mu}{s/\sqrt{n}}\sim t_{n-1}\end{aligned}\]t-검정
t-검정은 t-분포를 이용하여, 표본평균이 모평균과 유의미하게 다른지를 검증하는 통계적 방법이다. t-검정은 표본평균과 모평균의 차이가 우연히 발생할 수 있는 정도를 계산하여, 그 차이가 통계적으로 유의미한지를 판단한다.
크게 세 가지 유형의 t-검정이 있다.
- 단일표본 t-검정: 하나의 표본평균이 특정한 모평균과 다른지 검증한다.
- 독립표본 t-검정: 두 개의 독립된 표본평균이 서로 다른지 검증한다.
- 대응표본 t-검정: 같은 표본에서 두 개의 측정값이 서로 다른지 검증한다.
독립표본 t-검정
독립표본 t-검정은 두 집단의 분산이 같은지에 다른지에 따라 다른 검정 방법을 사용한다. 등분산이면 합동분산(Pooled Variance) t-검정을, 이분산이면 Welch’s t-검정을 사용한다. 때문에 $F$-검정으로 대상 집단이 등분산인지 이분산인지 먼저 검증한다. 일반적으로는 $p$-값이 0.05보다 작으면 이분산, 크면 등분산으로 판단한다.
$t$-검정의 $p$-값이 0.05보다 작으면, 두 집단의 차이는 통계적으로 유의미함을 의미로 해석할 수 있다. 이 경우 귀무가설인 “두 집단의 평균이 같다”를 기각한다. 반대로 $p$-값이 0.05보다 크면, 두 집단의 차이는 통계적으로 유의미하지 않음을 의미하여 귀무가설을 수용한다.
1
2
3
4
5
6
7
t.test(
groupA$쇼핑액,
groupB$쇼핑액,
paired=FALSE, # (기본값) 두 집단의 표본이 독립적임
var.equal=FALSE, # (기본값) 두 집단의 분산이 같다고 가정하지 않음
conf.level=0.95 # (기본값) 95% 신뢰구간
)
1
2
3
4
5
6
7
8
9
10
Welch Two Sample t-test
data: groupA$쇼핑액 and groupB$쇼핑액
t = 0.92362, df = 57.42, p-value = 0.3595
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-8.833426 23.962777
sample estimates:
mean of x mean of y
177.1418 169.5771
이 경우에는 $t$-값이 0.92362, 자유도가 57.42, $p$-값이 0.3595로 유의수준(0.05)보다 크고, 95% 신뢰구간 사이에 0이 포함되어 있기 때문에 귀무가설을 기각할 수 없다. 따라서, 두 집단의 평균은 통계적으로 유의미한 차이가 있다고 보기 어렵다.
대응표본 t-검정
대응표본 t-검정은 동일한 대상으로부터 얻은 페어로 이루어진 두 측정값을 비교하는 것이다. 어떤 집단에 대해 어떤 처치를 하기 전과 후의 표본을 비교하는 것, 예를 들어 동일 인물의 약물 복용 전과 복용 후 수치를 비교하는 경우가 대표적이다. 독립표본과 달리 두 집단이 서로 연결되어 있으므로 차이값 $d_{i}$ 의 평균이 0인지를 검정한다. 표본 수가 우연히 같은 것과 ‘대응’되는 것은 다른 개념임을 주의해야 한다.
그래서 다소의 비약을 거쳐서, 독립표본 t-검정은 표본 수가 다른 두 집단에 대한 비교, 대응표본 t-검정은 표본 수가 동일한 두 집단에 대한 비교로 설명하기도 한다. (물론 독립표본 t-검정에서도 표본 수가 동일한 집단에 대해 검정할 수 있으므로, 표본 수가 동일한 집단에 대한 검정이 대응표본 t-검정이라고 할 수는 없다.)
1
2
3
4
5
t.test(
data$쇼핑1월,
data$쇼핑2월,
paired=TRUE # 대응표본 t-검정
)
1
2
3
4
5
6
7
8
9
10
Paired t-test
data: data$쇼핑1월 and data$쇼핑2월
t = 1.7024, df = 89, p-value = 0.09216
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-0.644027 8.350694
sample estimates:
mean difference
3.853333
이 경우에는 $p$-값이 0.09216으로 유의수준보다 크므로 귀무가설을 기각하지 못한다. 처치 전후의 차이가 통계적으로 유의미하다고 할 수 없다.