4월 9일 MAPLE NOW에서 공개된 메이플스토리 확률 로직 내 모듈러 편향 이슈
발단이 된 영상
도입
4월 9일, 글을 작성하기 시작하는 오늘(실제로 언제 퇴고해서 올리게 될지 모르겠다.) 낮, 메이플스토리에서 진행하는 개발자 스트리밍 방송, 메이플 나우가 진행되었다.

이미 하루의 태반을 학교에서 지내며 집=자는 곳이 되어버린 나는 메이플스토리를 할 수 있을 리 없으므로, 친구들이 모인 톡방에서 이 오류 이슈를 처음 접하게 되었다.
요약하자면, 메이플스토리 확률 처리 시스템에 있어 전수 조사를 진행했고, 그 구현에 있어서 아직도 남아있는 문제가 있다는 것이었다.
다만 이번에 이슈가 된 배경에는, 그 원인을 설명하면서 본의 아니게 인터넷 강의가 열리게 되어 버리게 된 것이 클 것이다.
그래서 대략 유저들은 이러한 반응인 모양이다.. #
아래의 단락들은 컴퓨터공학 용어들이 여과없이 사용됩니다. 내용이 어려운 분께서는 각 단락 끝부분마다 비전공자 대상 쉬운 설명을 덧붙여두었으니 참고하시기 바랍니다.
문제의 원인
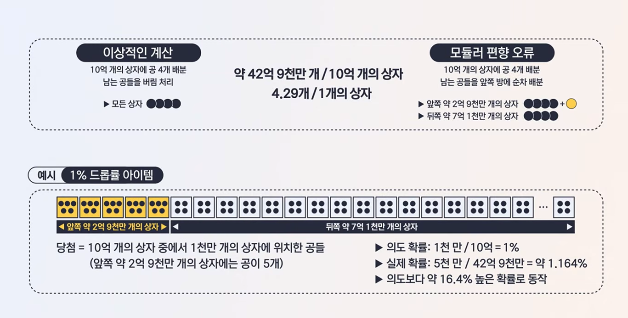
이번 확률 이슈의 원인으로는 “모듈러 편향”이라는 것이 지목되었다. 설명으로서 추정하건대, 아마 다음과 확률 로직이 구현되었던 것 같다.
1
2
3
4
5
6
// 32비트 난수 생성기
// [0, 0xFFFFFFFF] 범위의 난수를 반환한다고 가정
uint32_t rand_gen() {}
// 실제 확률 로직에서...
uint32_t result = rand_gen() % (uint32_t)1e9;
이와 같은 구현은 문제가 없어보이지만, 통계적으로는 대략 (0, 2억9천만) 범위의 값이 더 많이 나올 수 있다.
| 범위 | u32 에서 발생 가능한 수 |
|---|---|
| [0, 10억) | [0, 10억) |
| [10억, 20억) | [10억, 20억) |
| [20억, 30억) | [20억, 30억) |
| [30억, 40억) | [30억, 40억) |
| [40억, 50억) | [40억, $\approx$ 42억9천만) |
u32는 42억9천만까지의 값만을 표현할 수 있기 때문에, (42억9천만, 50억] 범위의 값은 생성되지 않는다.
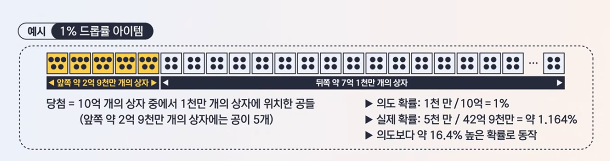
그래서 자료와 같이 “앞쪽 약 2억 9천만개의 상자에는 공이 5개, 그 뒤에는 공이 4개”라는 표현을 사용한 것이다.
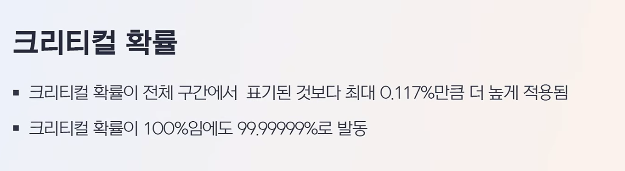
확률 로직과 관련해 또 다른 흥미로운 오류는 100%가 99.999…%로 처리되고 있었다는 것인데, 이것도 여과없이 단순 모듈러 연산 처리를 했을 때 어떠한 구현상 착오가 있지 않았을까 하는 생각이 든다.
(쉬운 설명) 모듈러 편향이란 무엇인가?
0부터 12까지의 숫자를 랜덤하게 하나 선택합니다. 그렇다면 0부터 12까지 나올 확률은 모두 동일합니다.
| 숫자 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 확률 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 |
그런데 이렇게 선택한 숫자에서 1의 자리수만 사용합니다. 그렇다면 그 결과로 0부터 9 사이의 임의의 수를 얻을 수 있습니다.
| 숫자 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1의 자리 수 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 2 |
이렇게 획득하는 수의 등장 확률은 균등하지 않습니다.
| 숫자 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 확률 | 2/13 | 2/13 | 2/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 | 1/13 |
굳이 42억9천만인 이유는, 메이플스토리 서비스 시작 당시 컴퓨터가 한 번에 처리할 수 있는 최대 숫자가 42억9천만이었기 때문입니다. (32비트 부호없는 정수)
같은 원리로, 메이플스토리의 사례입니다. 이번에는 0에서 약 42억9천만 사이의 숫자를 랜덤하게 하나 선택합니다. 그렇다면 0에서 약 42억9천만 사이의 숫자가 나올 확률은 모두 동일합니다.
| 숫자 | 0 | 1 | 2 | … | 4,294,967,294 | 4,294,967,295 |
|---|---|---|---|---|---|---|
| 확률 | 1/42.9억 | 1/42.9억 | 1/42.9억 | … | 1/42.9억 | 1/42.9억 |
그런데 이렇게 선택한 숫자에서 10억으로 나눈 나머지 수만 사용합니다. 그렇다면 그 결과로 0부터 999,999,999 사이의 임의의 수를 얻을 수 있습니다.
| 숫자 | 0 | 1 | 2 | … | 999,999,999 | 1,000,000,000 | 1,000,000,001 | … | 4,294,967,294 | 4,294,967,295 |
|---|---|---|---|---|---|---|---|---|---|---|
| 10억으로 나눈 나머지 수 | 0 | 1 | 2 | … | 999,999,999 | 0 | 1 | … | 294,967,294 | 294,967,295 |
이렇게 획득하는 수의 등장 확률은 균등하지 않습니다.
| 숫자 | 0 | 1 | 2 | … | 999,999,998 | 999,999,999 |
|---|---|---|---|---|---|---|
| 확률 | 5/42.9억 | 5/42.9억 | 5/42.9억 | … | 4/42.9억 | 4/42.9억 |
메이플스토리에서는 이 과정으로 획득한 0부터 999,999,999 사이의 숫자를 10억을 100%로 잡고 로직을 처리한 것으로 보입니다.
여담으로는, 크리티컬 확률에서도 100%가 99.999…%로 처리되는 문제가 있었다고 했습니다. 확실한 것은 아니지만, 이렇게 연산을 한 결과에서 획득할 수 있는 최대 수는 10억이 아니라 9.99억이므로, 역시 이것과 관계가 있을 지 모릅니다.
더 나아가 생각하기
만약 최초 판의 코드에서 사용된 난수 생성기가 코드에 노출되지 않고 어떠한 래퍼 함수로 감싸져있다고 한다면, 그래서 상당수 확률 처리 로직이 레거시 난수 생성기를 호출하고 있었다면, 아마 오랫동안 확률 처리에 rand(3)를 사용하고 있었을 가능성이 있다고 생각한다. 메이플스토리의 서비스 시작 시점을 고려하면, 수정을 거치지 않았다면, 레거시 코드에서는 C++ 11에서야 도입된 std::mt19937을 사용했을 것 같지는 않다.

설명 중에 u32 범위가 언급된 것으로 보아, 문제가 된 부분도 32비트 난수를 생성한 것으로 보이기는 한다. 하지만 MSVC 런타임에서 rand는 단일 호출 최대 0x7FFF까지 반환할 수 있다. 만약 rand를 사용해 32비트 난수 생성기를 구현했다면, 이 확률 로직은 32비트 엔트로피를 공급받는다고 보기에 어려우므로, 잠재적으로 또 다른 문제가 있을 수도 있지 않았을까 싶다.
물론 꼭 32비트 엔트로피가 만족되지 않는다고 해서, 모든 값의 분포가 균등하지 않게 되는 것은 아니다. 하지만 32비트 엔트로피를 공급받지 않는 난수 생성기가 32비트 수를 만들기 위해 사용하는 방식이, 이번 건처럼 또 어떤 잠재적인 문제가 있었을지도 모르는 법이다.
(쉬운 설명) 컴퓨터가 난수를 만드는 방법
컴퓨터는 그 한계가 명확한 단순 계산기입니다. 그래서 컴퓨터는 랜덤한 숫자를 아주 복잡한 계산식을 사용해 만듭니다. 아주 복잡할 뿐이지, 결국은 이미 계산하기도 전에 결과가 결정된 계산식입니다.
논리적으로 비약하자면, 예를 들어, 랜덤한 숫자를 만드는 데 사용하는 “복잡한 계산식”을 피보나치 수열이라고 가정해보겠습니다.
피보나치 수열은 0, 1로 시작해서, 다음 숫자는 이전 두 숫자의 합이 되는 수열입니다.
\[\begin{aligned} f(1) &= 0 & f(2) &= 1 & f(3) &= 1 & f(4) &= 2 \\ f(5) &= 3 & f(6) &= 5 & f(7) &= 8 & ... \end{aligned}\]한 번 숫자를 만들고 나서 다음 숫자를 만들 때, 다음 피보나치 수를 사용한다면, 일단 이미 생성한 수와 다음에 생성한 수는 다르기 때문에 “랜덤한 것 처럼” 보일 수 있습니다. 70 피보나치 수와 71번째 피보나치 수를 각각 획득해 뒤의 여섯자리 수만 사용한다고 하면 정말 랜덤해 보일 것입니다.
\[\begin{aligned} f(68) &= 72723460248141 \\ f(69) &= 117669030460994 \\ f(70) &= 190392490709135 \\ &= 72723460248141 + 117669030460994 \\ f(71) &= 308061521170129 \\ &= 117669030460994 + 190392490709135 \end{aligned}\] \[\begin{aligned} f(68)_\text{trailing(6)} &= 248141 \\ f(69)_\text{trailing(6)} &= 460994 \\ f(70)_\text{trailing(6)} &= 709135 \\ f(71)_\text{trailing(6)} &= 170129 \\ \end{aligned}\]실제로는 매우 복잡한 계산식에다가, 최대한 랜덤성을 갖도록 온갖 트릭을 사용해서 구현하므로, 일상에서는 랜덤한 것으로 받아들일 수 있는 수준입니다. 하지만 지금까지의 설명과 메이플스토리의 최초 서비스 시점인 2003년의 상황을 고려하면, 지금까지 전제하고 있는 “0부터 약 42억 9천만 사이를 랜덤하게 하나 선택하는 로직”도 원본 계산식을 수정해서 구현한 것일 가능성이 있습니다. 메이플스토리에서 지금까지 사용했을 것으로 예상되는 계산식은 42억 9천만만큼의 큰 수를 생성하지 못했을 것으로 보이기 때문입니다.
그래서 42억 9천만의 숫자를 생성할 수 있도록 계산식을 수정했다고 가정하면, 이번에 발견된 문제 외에 또 다른 잠재적인 문제를 가지고 있을지도 모른다는 생각을 하게 되는 것입니다.
(쉬운 설명) 그럼 왜 확률 처리를 실수가 아니라, 왜 수십억 정수의 곱과 나눗셈으로 구현했을까요?
그냥 단순히 랜덤하게 0부터 100사이의 실수를 하나 뽑아서 그 숫자가 특정한 확률보다 작은지 비교하면 되는 것 아닌가요? 라고 할 수도 있습니다.
0.5% 확률로 성공하는 확률 로직
이렇게 구현하지 않고 위에서와 같이 10억이니 50억이니 하는 이유는, 컴퓨터에서 실수 연산이 정밀하지 않아 정확한 확률 계산이 어려울 수 있기 때문입니다.
역시 많은 비약이, 사실상 틀린 표현이긴 합니다만, 컴퓨터에서 실수 표시는 결국에는 정수 표시를 “어떻게 잘 조정해서” 실현하고 있습니다. 이 어떻게 잘 조정해내는 방법이, 예측하지 못한 버그가 종종 발생하기 때문에, 차라리 그냥 정수로 확률 계산을 해버리는 것입니다. 자세한 내용은 “부동소수점수”를 검색해보거나 영상을 참고해보세요.
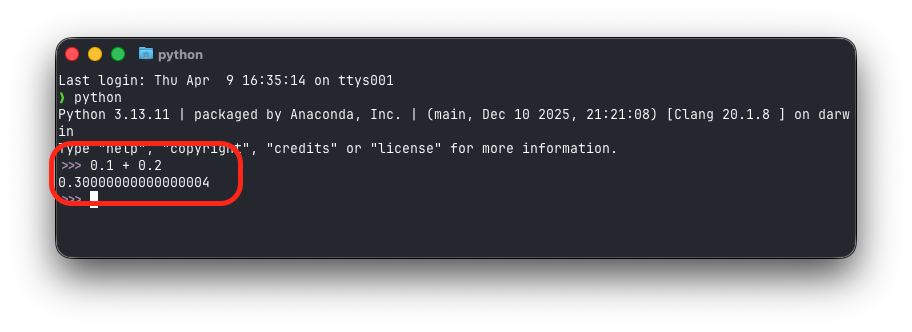
널리 알려진 오류 사례: 0.1 + 0.2의 결과가 0.3이 아닌 0.30000000000000004로 나오고 있습니다.
이러한 수 정밀도 문제는 익히 알려진 문제이고, 이 문제를 방지하는 가장 기본적인 전략 중 하나가 실수를 정수화 해 계산하는 것입니다. 때문에 이러한 정밀도 문제를 해결하는 데 있어서, 가장 먼저 취하는 방법이 이러한 계산 방법인 것입니다.
‘백준 온라인 저지’라는 프로그래밍 문제 풀이 사이트나 다른 비슷한 프로그래밍 대회, 문제풀이 사이트에서도 이러한 문제와, 정수화 계산 접근 방법은 자주 등장하는 기본 테크닉입니다.
(쉬운 설명) 그래서 왜 이렇게 코드를 작성했을까요? 왜 이 문제가 발견되지 않았죠?
사실 정확한 이유는 그 코드를 작성한 당사자만 알고 있겠습니다만, 적어도 당시에는 잠재적으로 문제있어 보이지 않았을 것입니다.
\[r \xleftarrow{\$}[0, 10^9]\] \[\text{f}(r) = \begin{cases} \text{success} & \text{if } r < 10^7 \\ \text{failure} & \text{otherwise} \end{cases}\]1% 확률로 성공처리되는 확률 로직
$r$ 이 0부터 10억 사이의 수에서 랜덤하게 선택된다고 생각하게 되면, 이제 더 이상 $r$ 이 실제로 어떻게 수를 생성하는지는 관심이 없었을 것입니다. 확률을 의도대로 설정하거나 조정하는 데 관여하는 로직과, 확률 테이블은 랜덤 숫자를 생성하는 것과는 다른 부분에서 관여하기 때문입니다.
“몇 퍼센트 확률로 성공/실패”를 처리하는 로직은 랜덤 숫자를 생성하는 데에서 이루어지지 않습니다. 보통 생성된 랜덤 숫자가 그래서 어떤 수보다 큰지 작은지 비교하면서 확률 처리가 이루어지기 때문입니다. 이 수를 어떻게 잡는지에 따라 성공 확률을 조정합니다.
| 범위 | 범위의 길이 | 확률 | 항목 |
|---|---|---|---|
| [0, 3.1천만) | 3.1천만 | $\frac{3.1\text{천만}}{100\text{천만}}=3.1\%$ | [스페셜 라벨] 트윙클 빈티지 (남자만 획득가능) / 핑크 위시 (여자만 획득가능) |
| [3.1천만, 6.3천만) | 3.2천만 | $\frac{3.2\text{천만}}{100\text{천만}}=3.2\%$ | [스페셜 라벨] 레이어드 메모리즈 (남) / 블루밍 버블검 (여) |
| [6.3천만, 9.5천만) | 3.2천만 | $\frac{3.2\text{천만}}{100\text{천만}}=3.2\%$ | [스페셜 라벨] 퓨어 화이트 슬립온 (남) / 코랄 레그 워머 부츠 (여) |
| [9.5천만, 12.5천만) | 3.0천만 | $\frac{3.0\text{천만}}{100\text{천만}}=3.0\%$ | [스페셜 라벨] 네오 레트로 갤럭시 |
| [12.5천만, 15.0천만) | 2.5천만 | $\frac{2.5\text{천만}}{100\text{천만}}=2.5\%$ | [스페셜 라벨] 스위트 밀키 웨이 |
| [15.0천만, 17.0천만) | 2.0천만 | $\frac{2.0\text{천만}}{100\text{천만}}=2.0\%$ | 레트로 카세트 크로스백 |
| [17.0천만, 18.5천만) | 1.5천만 | $\frac{1.5\text{천만}}{100\text{천만}}=1.5\%$ | 빈티지 프레임리스 안경 (남자만 획득가능) / 팝핑 스타 페이스 페인팅 (여자만 획득가능) |
| [18.5천만, 22.5천만) | 4.0천만 | $\frac{4.0\text{천만}}{100\text{천만}}=4.0\%$ | 레드 문 매지션 페도라 (남자만 획득가능) / 레드 문 매지션 햇 (여자만 획득가능) |
| [22.5천만, 25.0천만) | 2.5천만 | $\frac{2.5\text{천만}}{100\text{천만}}=2.5\%$ | 레드 문 매지션 로브 (남) / 레드 문 매지션 원피스 (여) |
| (이하 생략) | … | … | … |
100%를 10억이라고 했을 때, [0, 10억) 범위의 랜덤 정수를 활용한 확률 처리, 확률 테이블 설정 예시 (메이플스토리 확률형 아이템 로얄스타일 2026-04-10 기준 표 참고)
해결
스트리밍에서는 모듈러 편향 문제에 있어서 “버린다”는 표현이 사용되었는데, 여러 측면에서 해결할 수 있을 것이다.
가장 러프한 구현을 고려하면, 거부 샘플링을 직접 구현하는 방법이다.
1
2
3
4
5
uint32_t gen;
do {
gen = rand_gen();
} while (gen >= (uint32_t)4e9); // 40억보다 큰 값이 나오면 다시 난수 생성
uint32_t result = gen % (uint32_t)1e9;
사실 std::uniform_int_distribution을 사용하면, 내부적으로 거부 샘플링이 구현되어 있기 때문에, 간단히 다음과 같이 구현할 수도 있다.
1
2
3
4
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<uint32_t> dis(0, 999999999);
uint32_t result = dis(gen);
이렇게 하면 고품질의 난수 생성기도 사용할 수 있고, 모듈러 편향 문제도 해결할 수 있다. (<더 생각하기>가 참이라는 가정 하에)
사실 참이 아니어도 std::mt19937이나 그에 준하는 고품질 난수 생성기를 사용하고 있을 것이므로, std::uniform_int_distribution나 그것과 비슷한 구현을 이미 사용하고 있을 것이다.
(쉬운 설명) 그래서 어떻게 해결하나요?
이 문제는 0부터 42억9천만 사이의 숫자를 10억으로 나눈 나머지를 사용해서, 0부터 2억9천만 사이의 숫자가 더 많이 등장할 수 있는 데에서 발생했습니다.
그렇다면, 처음부터 이 수를 분모, 10억에 나누어 떨어지게 생성하여 등장 횟수를 균등하게 만들어 해결할 수 있습니다. 스트리밍에서도 남은 것을 버린다는 표현이 있었는데, 등장하는 수를 0부터 39.99..억([0, 40억) 범위) 사이의 숫자로 제한한다는 의미로 해석할 수 있을 것 같습니다.
| 숫자 | 0 | 1 | 2 | … | 294,967,295 | 294,967,296 | … | 999,999,998 | 999,999,999 |
|---|---|---|---|---|---|---|---|---|---|
| 이전 확률 | 5/42.9억 | 5/42.9억 | 5/42.9억 | … | 5/42.9억 | 4/42.9억 | … | 4/42.9억 | 4/42.9억 |
| 새로운 확률 | 4/40억 | 4/40억 | 4/40억 | … | 4/40억 | 4/40억 | … | 4/40억 | 4/40억 |
“남는 공을 앞쪽 상자에 넣어 다섯개 공을 만들지 않고, 그대로 버린다”는 표현이 이러한 맥락에서 나왔습니다.
이것을 구현하는 방법은 여러 개 있을 수 있겠습니다만, 생각할 수 있는 가장 간단한 방법은 39.99..억보다 큰 숫자가 나오면 39.99..억 아래의 수가 나올 때까지 다시 난수를 생성하는 것입니다.
오늘날에 와서는 프로그래밍 언어* 단에서 기본적으로 고품질의 난수 생성기를 제공하기 때문에, 그것으로 교체하는 것만으로도 지금까지의 문제를 해결할 수 있습니다. <더 나아가 생각하기>, <(쉬운 설명) 컴퓨터가 난수를 만드는 방법> 에서의 우려 역시 이렇게 하는 것만으로도 해소할 수 있습니다.
*정확히는 표준 라이브러리
의견
실제로 이번 문제의 원인은 주의깊게 살피거나 고민하지 않으면 지나치기 쉬운 문제였다. 국내 유수의 게임 회사에서 벌어질 버그가 아니라고 주장하기에는, 당시 문제의 코드를 작성한 개발자들은 지금의 기준으로 주니어로 분류되는 수준의 경력이었을 것이었음을 고려할만 하다.*1
*1 넥슨 회고록 《플레이》에 미루어 보았을 때, 당시 개발진들의 업계 경력은 절대 길다고 할 수 없다.
개인적으로는 이 문제의 설명을 들으면서, 이따금 테크 뉴스에 “잠재적으로 문제가 있음” 이나 “시스템 커널 어딘가에서 발굴해낸 버그”로 소개되는 버그들이 떠오르게 되었다. 동일 선상에 놓을 수는 없겠지만은, 그런 기분이었다.
아무튼 위의 추측이 참이라고 한다면, 감히 생각하건대 메이플스토리 뿐 아니라 상당수 게임, 특히 인디게임 쪽에서.. 동일한 문제가 잠재되어 있을 가능성이 있다고 생각한다. 알법한 게임들 중에 한 두개 작품에서는 이런 문제가 있지 않을까.
근데 아무리 그래도 나머지 계산에 분모를 10억 가까이 잡는건 조금 신선했다. 아직 학생이니 프로덕션에서 실제로 어떻게 돌아가는지는 모르겠지만, 대부분의 유즈케이스에서 나눗셈의 분모는 많아봐야 대여섯자리라고 생각했기 때문에..