하드웨어 과적합 접근으로 Mass Spring Damper 시스템 최적화하기
도입
기말고사를 ‘본인만의 수치적분법(Numerical Integration)을 물리 시뮬레이션에 적용하는 텀프로젝트’로 대체합니다.
…
평가 기준 시뮬레이션의 완성도는 아래 3가지 항목을 기준으로 평가하며, 만족도가 높을수록 고득점을 부여합니다.
- 시간 간격(Time-step)의 강인성: 타임스텝이 커져도 시뮬레이션이 터지지 않고 안정적으로 유지되는가
- 강성(Stiffness)의 강인성: 높은 강성 값에서도 수치적 불안정성 없이 안정적인 거동을 보이는가
- 거동의 사실성: 실제 물리 현상과 얼마나 유사하고 사실적으로 표현되는가
평가 시나리오 (총 3개) 제공된 템플릿 프로젝트 내의 모든 시나리오(총 3종)에서 본인의 수치적분법이 정상 작동하고 위의 평가 기준을 만족해야 합니다.
- 천(Cloth) 시뮬레이션: 중력(Gravity) 조건 하에서만 구동 및 평가
- 볼륨 메쉬(Volume Mesh) 시뮬레이션: 중력(Gravity) 조건 하에서만 구동 및 평가
- 1자유도(1-DoF) 스프링 시뮬레이션: 사용자 입력(User Input)에 따른 외력이 작용하는 상태에서 구동 및 평가
… (후략)
학교의 가상현실 수업에서 Mass-Spring-Damper 시스템의 수치적분 계산을 수단과 방법을 가리지 않고 최적화하는 기말고사 대체과제를 수행하였다. 수치적분 수식의 구성 요소를 수정해도 되고, 새로운 수치적분법을 고안하거나, 아예 새로운 제 3의 접근을 시도해도 되었다.
이 과제에 대해서 최적화 대상을 특정한 하드웨어, 이 과제에서는 프로젝트를 시연할 컴퓨팅 환경으로 고정하고, 그 하드웨어에 대해서만 과하게 최적화하는 방법으로 작업을 수행하였다.
이러한 방법은 하드웨어가 고정된 플랫폼의 소프트웨어를 개발할 때 유용하게 쓰인다. 예를 들어 콘솔 게임기의 하드웨어 스펙이 일반적인 게이밍 PC보다 낮음에도 불구하고, 콘솔 게임은 PC에 준하거나 그보다 나은 성능을 보인다. 이는 콘솔 게임기의 하드웨어에 맞춰 최적화된 소프트웨어를 개발했기 때문이다.
단일 플랫폼(좋은 예로 Xbox가 있습니다)으로 수년간 일했던 개발자가 있다고 합시다. 수년이라면 해당 플랫폼에서 통하는 흑마법을 익히기에 충분합니다.
《C++ 최적화》, 커트 건서로스 저(옥찬호 역), 2019.
따라서 하드웨어를 고정했다는 전제 하에, 시연이 이루어질 컴퓨팅 환경, AMD Ryzen 5 5600 6-Core Processor (12 CPUs), ~3.5GHz, NVIDIA GeForce RTX 3050 (VRAM 8GB), 32GB 메모리 환경에 대해 Mass-Spring-Damper 시스템의 수치적분 계산을 최적화했다.
과제 템플릿으로써 주어진 것은 변형 없이 개념 그대로의 Explicit Euler Method를 사용한 C# MonoBehaviour 구현이었다. MonoBehaviour는 일반적으로 CPU에서 동작하므로, 이 시도에서는 GPU를 사용하도록 하고, RTX 3050의 하드웨어 스펙에 맞춰 계산 동작을 수행하도록 최적화했다.
배경
물리 계산 기반 그래픽 렌더링 방법에서는 물리 시뮬레이션을 계산하면서 위치 $x$, 속도 $\dot{x}$, 가속도 $\ddot{x}$ 를 계산한다. 이 방법에서는 대개 $\ddot{x}$ 로부터 $\dot{x}$ 를, $\dot{x}$ 로부터 $x$ 를 계산하게 되면서, 적분 계산 처리가 요구된다.
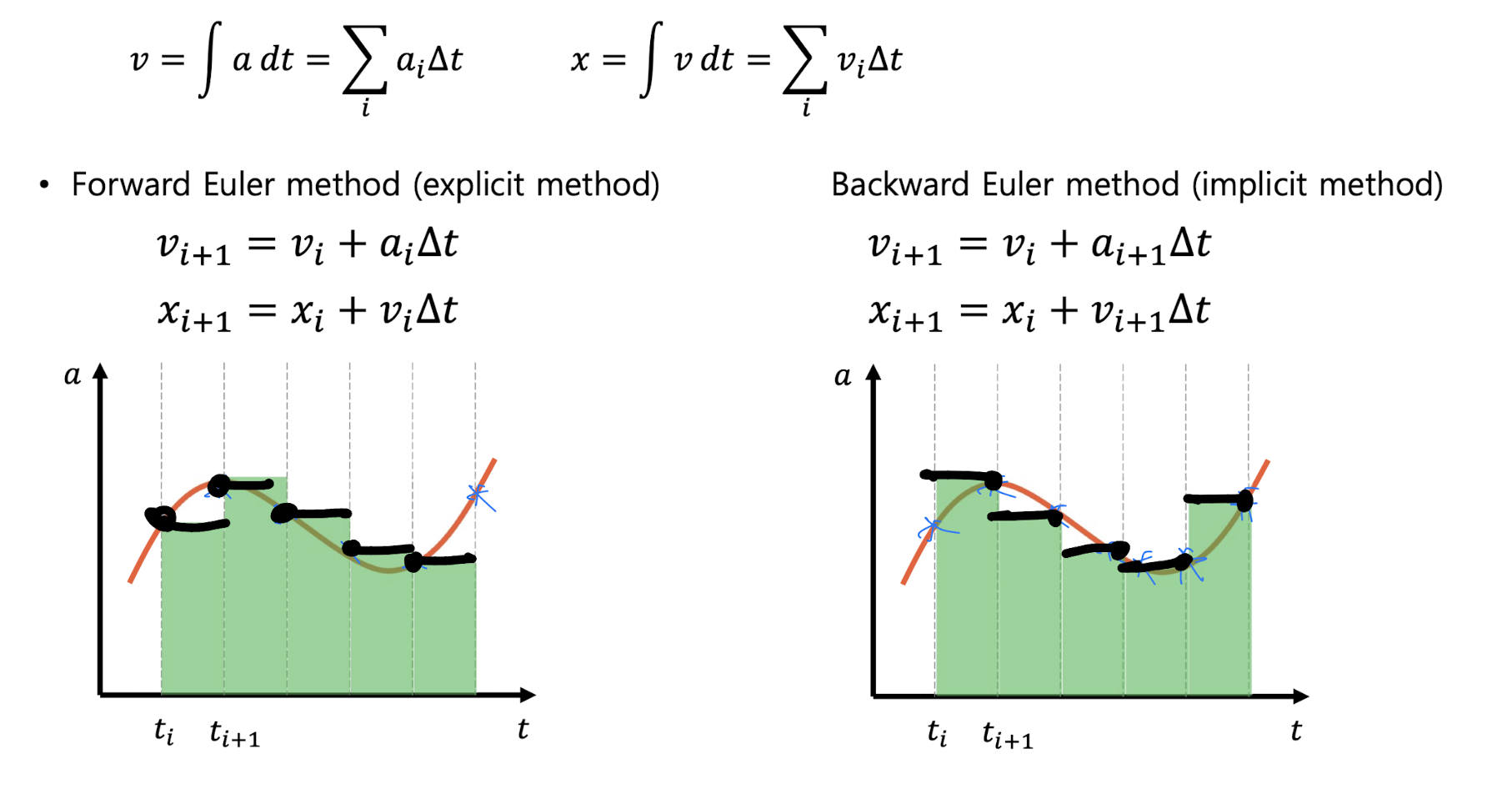
문제는 컴퓨터에서는 수학적 의미에서의 적분을 정확하게 수행할 수 없다는 점이다. 컴퓨터에서는 연속한 값을 다룰 수 없으므로, 연속 값을 잘게 쪼개어 계산하는 수치적분법(Numerical Integration)을 사용하게 된다.
하지만 수치적분법은 결국 연속값을 근사하는 것이므로, 실제 기대값과 오차가 발생할 수밖에 없다. 만약 시스템에서 오차가 적절히 해결되지 않고 점차 누적된다면 시뮬레이션은 불안정해지고 이윽고 모델이 터져나가는 것처럼 보이게 된다.
이러한 상황을 막기 위해서는 오차가 최대한 적은 수치적분법과 연속값을 더욱 최대한 잘게 쪼개는 방법을 사용해야하나, 필연적으로 연산량이 많아지고 계산속도가 매우 느려지게 된다. 특히 초당 최소 30프레임 이상은 보장해야 하는 현대의 게임 환경이나 실시간 가상현실에서 이러한 단점은 매우 치명적이다.
따라서 실제로는 렌더링에서 물리 시뮬레이션을 대신 다른 방법을 채택하거나, 이 수치적분 식을 변형하여 새로운 수치적분법을 정의해 오차를 최소화하려고 한다.
방법론

간략화된 구현 구조
이번 시도에서는 CPU에 의해 처리되는 MonoBehaviour 구현을 GPU에서 처리하도록 하고, 발산 문제로부터 상대적으로 자유로운 Implicit Euler Method를 사용하도록 수치적분법을 변형했다. 또한 이 GPU 처리에 대해서 조금 더 설계 환경에 맞춰 최적화할 수 있도록 CUDA 처리를 구현하고 동적 링크하여 유니티 런타임에서 사용했다.
이 작업 구현의 최적화 대상 PC 환경은 다음과 같다.
| 항목 | 사양 |
|---|---|
| CPU | AMD Ryzen 5 5600 6-Core Processor (12 CPUs), ~3.5GHz |
| RAM | 32GB |
| GPU | NVIDIA GeForce RTX 3050 (VRAM 8GB) |
| OS | Windows 11 Education |
| CUDA | CUDA 13.2 |
RTX 3050 (8GB) 과적합 최적화
float4 사용
NVIDIA GPU의 어셈블리 명령어에는 128비트의 데이터를 한 번에 로드할 수 있는 LDG.E.128 명령어가 있다. 만약 float 값을 4개 로드해야 한다면, 32비트 데이터를 로드하는 LDG.E.32 명령을 4회 호출하는 것 대신 128비트 로드 명령을 1회 호출하는 것이 처리량을 더 높일 수 있다.
float4 데이터 타입은 16바이트(128비트)로 크기로 구성된 벡터 타입으로, 이 데이터 타입을 사용하면 위의 LDG.E.128(store는 STG.E.128) 명령으로 컴파일된다. 주소가 16바이트에 맞춰 정렬되어있고, 접근 패턴이 연속적이라면, GPU는 메모리 접근을 벡터화하여 128비트 단위로 데이터를 고속으로 읽고 쓸 수 있다. 12
스레드 당 레지스터 사용량 제한(__launch_bounds__)
Mass-Spring-Damper 시스템의 계산 커널에서 Point-wise 연산을 많이 사용하였다. Point-wise 연산은 각 원소에 대해 독립적으로 수행되어, 메모리 접근 패턴이 단순하고 병렬화하기 쉽다. 그러나 여러 개의 Point-wise 연산이 하나의 커널 안에서 연속적으로 수행되면, 각 중간 계산값을 저장하기 위해 스레드당 필요한 레지스터 수가 증가할 수 있다.
GPU에서 레지스터는 각 스레드가 가장 빠르게 접근할 수 있는 저장 공간이다. 따라서 중간 변수나 반복적으로 사용되는 값들을 레지스터에 저장하면 메모리 접근 비용을 줄일 수 있다. 하지만 레지스터는 Streaming Multiprocessor(SM)마다 사용할 수 있는 레지스터 파일의 크기가 제한되어 있다. 한 스레드가 사용하는 레지스터 수가 많아질수록 하나의 SM에 동시에 배치될 수 있는 스레드, 워프의 수는 줄어든다.
주목할 점은 RTX 3050의 SM당 레지스터 파일 크기가 64K개의 32-bit 레지스터라는 점이다. 이는 한 SM에서 동시에 실행되는 모든 스레드가 공유하는 레지스터 자원이다. 예를 들어, 하나의 스레드가 사용하는 레지스터 수가 적다면 더 많은 워프가 동시에 SM에 상주할 수 있다. 반면, 스레드당 레지스터 사용량이 커지면 동일한 64K 레지스터 파일 안에서 수용 가능한 스레드 수가 감소하게 된다.
이것은 GPU의 병목으로 발전할 수 있다. 하나의 SM에서 동시에 실행되는 워프 수가 적으면, 메모리 접근이나 연산이 완료될 때까지 기다리는 동안 다른 워프가 실행되지 못해 GPU의 유휴 시간이 증가한다. 이어서 전체적인 처리량을 감소시키고, 결과적으로 성능 저하로 이어진다.
그래서 이 구현에서는 병목을 피하기 위한 방법으로 스레드 당 레지스터 수를 제한하도록 하였다. 블록당 최대 256개의 스레드, 하나의 SM에 최소 2개의 블록이 상주하도록 컴파일러에 레지스터 사용 상한 추론 힌트를 주었다.
\[256 \times 2 = 512 \text{ threads per SM}\]RTX 3050의 SM 당 레지스터 파일 크기, 64K개의 32-bit 레지스터를 고려하면, 스레드당 레지스터 수의 상한은 대략 128개 즈음으로 계산 가능하다.
\[\frac{64 \times 1024}{256 \times 2} = 128 \text{ registers per thread}\]읽기 전용 데이터로 플래그 (__ldg)
커널 실행 중 값이 변하지 않는 입력 버퍼, 예컨대 rest length, 질량 등은 읽기 전용 접근으로 취급할 수 있다. 이들에 대해 const __restrict를 부여하고, __ldg()를 사용해 read-only data cache load 경로를 사용하도록 힌트하였다. 컴파일러가 읽기 전용 조건이 충족되는지 감지하도록 하는 데 있어 __ldg를 사용하면, 조건을 검사해 L1 캐시를 활용하도록 유도할 수 있다.34
L2 persisting cache limit 설정 (cudaDeviceSetLimit)
Mass-Spring-Damper 시스템의 implicit 적분 경로는 conjugate gradient(CG) solver를 반복 수행하면서, 동일한 상수 데이터—스프링 양 끝점 인덱스, 선형화 계수, 질량, 각 점의 상태 표현 마스크—를 매 반복마다 다시 읽는다. 이 데이터는 한 스텝 동안 값이 바뀌지 않으므로, 매 CG 반복 과정에서 메모리까지 다시 내려가 읽는 대신 L2 캐시에 머무르게 할 수 있다면 메모리 지연과 대역폭 압박을 크게 줄일 수 있다.5
RTX 3050이 기반하고 있는 NVIDIA Ampere 아키텍처는 L2 캐시 내 데이터 잔류(residency)를 제어할 수 있다. 그래서 이 구현에서는 L2 전체 용량의 75%를 persisting 데이터용 예산으로 산정하고 예약 설정했다. 75%는 임의로 설정한 값으로, 일반 데이터가 L2 캐시를 사용할 수 있도록 여유를 남기기 위해 25%를 남겨두었다.6
구체적으로 cudaDeviceSetLimit을 사용해 제한을 설정했는데, 이 방법으로는 영역의 크기를 예약하는 정도만 수행할 수 있다. 따라서 어떤 버퍼가 실제로 L2에 우선 보존할 수 있게 대상 주소 범위를 persisting으로 플래그하는 접근 정책을 함께 적용하였다. (cudaAccessPolicyWindow의 hitProp = cudaAccessPropertyPersisting)
분기에서 비롯되는 제어 해저드 최소화
주어진 수치적분 처리와 Mass-Spring-Damper 시스템을 따르는 예제 모델에서는 몇 개 점을 고정시켜놓고 나머지 점만 움직이도록 하여 움직임을 확인하는 시나리오가 있다. 이 때 사전에 주어진 구현에서는 고정 점을 처리하기 위해 분기문을 사용했는데, 잠재적으로 branch divergence가 발생할 수 있다.
\[x' = \begin{cases} 0, & \text{if } x \text{ is fixed} \\ x, & \text{otherwise} \end{cases}\]따라서 지금 처리하려는 점이 고정되는지 여부를 불리언 플래그 대신 스케일 값으로서 연산 처리하여 분기가 발생하지 않도록 했다.
내적 계산 중 부분합 처리 (__shfl_down_sync, cooperative_groups::memcpy_async)
시스템의 수치적분 계산에서는 내적 계산이 반복적으로 사용되고 있다. 병렬 처리 효율을 위해 스레드별로 데이터를 분할해 병렬로 내적 처리시킬 수 있는데, 이 때 각 스레드의 곱셈 결과를 합산하는 부분합 reduction 과정이 수행되어야 한다.
warp shuffle을 이용한 reduction
이 과정을 위해 데이터를 공유 메모리로 옮겨 처리할 경우, 공유 메모리에 값을 저장하고 다시 읽는 load/store 연산이 필요하고, 주소를 보관하거나 계산하기 위한 추가 레지스터도 요구되므로 메모리 접근 오버헤드가 발생한다. CUDA에서는 공유 메모리에 접근하지 않고 같은 warp 내부의 다른 lane의 값을 가져올 수 있는 warp shuffle 함수 __shfl_down_sync를 제공한다. 이것을 활용해 부분합 과정의 스레드 간 데이터 교환을 효율적으로 수행할 수 있다.7
블록별 부분합의 후속 reduction에서 비동기 복사 사용
하나의 스레드 블록만으로 전체 입력에 대해 reduction을 수행하려고 하면 블록 하나가 처리할 수 있는 스레드 수의 한계로 인해, 소수의 블록만 실행되어 SM 대부분이 유휴 상태로 남게 된다. 따라서 대규모 데이터 입력을 처리하게 되는 부분을 분리해 위의 __shfl_down_sync를 사용하도록 하고, 이후 각 블록에서 계산된 부분합을 다시 reduction하도록 만들었다.
서로 다른 block의 값을 합산할 때는 __shfl_down_sync를 사용할 수 없다. __shfl_down_sync는 같은 warp 내부 lane 사이의 레지스터 값 교환만 지원하기 때문이다. 따라서 각 block에서 계산한 부분합은 global memory에 저장하고, 이후 별도의 reduction 단계에서 이 값을 다시 읽어 처리해야 한다. 이때 다음 단계의 커널에서는 블록별로 처리된 부분합 데이터를 공유 메모리로 staging한 뒤 블록 내부 reduction을 수행할 수 있다.8
공유 메모리를 사용하는 과정 중에, 동기적인 복사를 사용하면 데이터가 공유 메모리에 준비될 때까지 스레드들이 대기하여 메모리 지연이 그대로 노출된다.
그래서 데이터를 비동기적 복사 구현 cooperative_groups::memcpy_async를 사용하여, 복사와 계산을 겹치도록 만들었다. 이 구현을 사용하면 복사가 진행되는 동안 이전에 준비된 데이터에 대한 계산을 수행하도록 구성할 수 있다.9
shared memory carveout 선호 설정
RTX 3050과 같은 Ampere 계열 GPU에서는 각 SM의 on-chip memory가 L1 cache와 공유 메모리 두 역할을 모두 수행할 수 있게 하는 unified data cache 구조를 갖는다. CUDA는 이 자원을 커널 단위로 L1 cache와 공유 메모리 중 어느 쪽에 더 많이 배분할지에 대한 선호 설정을 제공한다. 본 구현에서는 cudaFuncSetAttribute(..., cudaFuncAttributePreferredSharedMemoryCarveout, ...)와 cudaFuncSetCacheConfig(..., cudaFuncCachePreferShared)를 사용하여 커널 단위에서 공유 메모리를 선호하도록 설정하였다.1011
특히 내적 과정 중의 부분 커널 DotPartialKernel과 부분합을 reduce하는 커널 ReducePartialSumKernel은 reduction 과정에서 공유 메모리를 직접 사용한다. DotPartialKernel은 warp별 부분합을 저장하기 위해 공유 메모리 버퍼를 사용하고, ReducePartialSumKernel은 트리 reduction을 위해 버퍼와 cooperative_groups::memcpy_async의 global-to-shared staging 영역을 사용한다. 따라서 이들 커널에서는 L1 캐시보다 공유 메모리 용량 확보가 성능상 더 중요하다.
이에 따라 공유 메모리를 사용하는 reduction 계열 커널에는 cudaFuncAttributePreferredSharedMemoryCarveout 값을 100(아키텍처가 지원하는 최대치 100%로 공유 메모리 carveout을 선호하라는 의미이다.)으로 설정하여 공유 메모리 편에 자원을 배분하는 것을 선호하도록 하였고, cudaFuncSetCacheConfig에는 cudaFuncCachePreferShared를 지정하였다. 이와 같이 SM의 L1-공유 메모리 자원 중 가능한 많은 부분을 공유 메모리로 배분하는 것을 선호하도록 힌트하였다.
반면 공유 메모리를 사용하지 않는 점별 연산, 스프링 연산, 벡터 갱신 및 결과 커밋 커널에는 동일한 설정을 적용하지 않았다. 이러한 커널들은 주로 global memory의 read-only 데이터를 __ldg 등을 통해 읽는 방식이 지배적이므로, 공유 메모리를 불필요하게 크게 설정하면 오히려 L1 캐시로 사용할 수 있는 용량이 줄어들 수 있다. 따라서 공유 메모리를 사용하지 않는 커널에는 carveout을 공유 메모리 최소 선호 방향으로 설정하고, L1 캐시를 우선하도록 구성하였다.
이와 같이 공유 메모리 사용 여부에 따라 커널을 구분하여 차등 적용했다. 공유 메모리를 사용하는 reduction 및 협조적 복사 커널에는 공유 메모리 선호 설정을 적용하고, 공유 메모리를 사용하지 않는 연산 중심 커널에는 L1 캐시 선호 설정을 적용함으로써 각 커널의 메모리 접근 특성에 맞는 온칩 메모리 활용을 유도하였다.
결과
하드웨어 스펙은 최적화 작업을 수행한 후, 각 작업으로부터 획득한 구체적인 최적화 이득은 엄밀하게 평가하지 못했다.
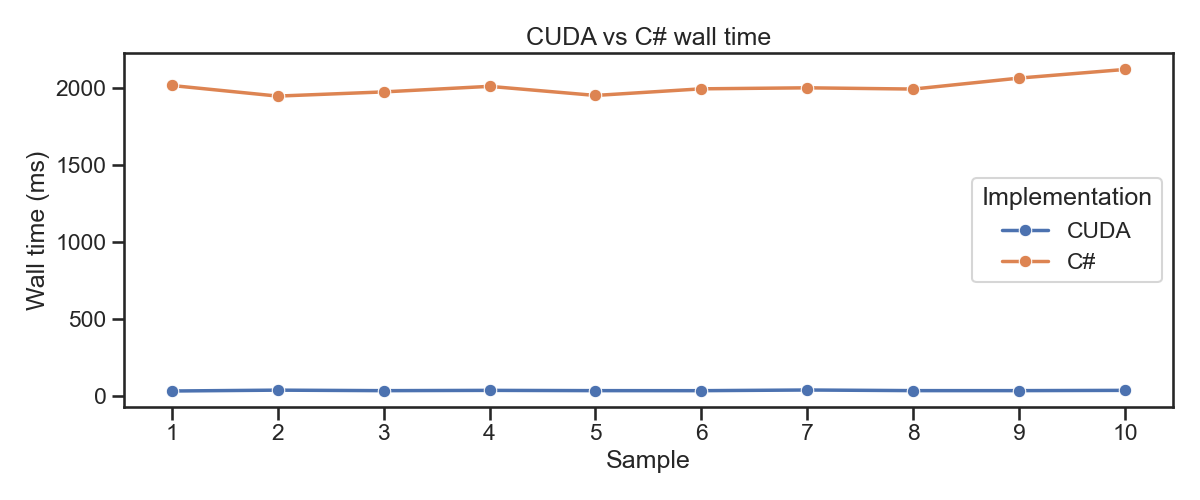
최초에 주어진 Mass-Spring-Damper 시스템의 수치적분 구현에서 유니티 의존성을 제거한 C# 구현과 이 작업물을 벤치하여 대략적인 성능 향상 수준을 측정하긴 하였으나, 두 구현은 매우 큰 차이가 나므로, 각각의 최적화 작업이 얼마나 성능 향상에 기여했는지 자세히 판단하는데 자료로 사용할 수는 없었다. 각 전략의 성능 향상 기여도를 평가했어야 했다는 것이 이 작업에서 앞으로의 과제라고 생각한다.
“5.4.2.3. Built-in Types”, CUDA C++ Programming Guide https://docs.nvidia.com/cuda/cuda-programming-guide/05-appendices/cpp-language-extensions.html#built-in-types ↩
Justin uitjens, Rajeshwari Devaramani, “CUDA 활용 팁: 벡터화된 메모리 접근으로 성능 향상하기”, NVIDIA 테크니컬 블로그 https://developer.nvidia.com/ko-kr/blog/cuda-pro-tip-increase-performance-with-vectorized-memory-access/ ↩
“Global Memory” CUDA C++ Progrmming Guide, https://docs.nvidia.com/cuda/cuda-c-programming-guide/#global-memory-5-x ↩
“Read-Only Data Cache Load Function”, CUDA C++ Programming Guide, https://docs.nvidia.com/cuda/cuda-c-programming-guide/#ldg-function ↩
“4.13. L2 Cache Control” CUDA Programming Guide, https://docs.nvidia.com/cuda/cuda-programming-guide/04-special-topics/l2-cache-control.html ↩
“4.13.4. L2 Persistence Example”, CUDA Programming Guide, https://docs.nvidia.com/cuda/cuda-programming-guide/04-special-topics/l2-cache-control.html#l2-persistence-example ↩
Yuan Lin, Vinod Grover, “Using CUDA Warp-Level Primitives” NVIDIA Technical Blog, https://developer.nvidia.com/blog/using-cuda-warp-level-primitives/ ↩
Mark Harris, “Optimizing Parallel Reduction in CUDA” Optimizing Parallel Reduction in CUDA ↩
“Cooperative Groups”, CUDA Programming Guide, https://docs.nvidia.com/cuda/cuda-programming-guide/04-special-topics/cooperative-groups.html ↩
“5.3. Memory Hierarchy” CUDA C++ Programming Guide, Release 13.3, https://docs.nvidia.com/cuda/pdf/CUDA_C_Programming_Guide.pdf ↩
“cudaFuncSetCacheConfig, 6.7. Execution Control” CUDA Toolkit Documentation, https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__EXECUTION.html#group__CUDART__EXECUTION_1g6699ca1943ac2655effa0d571b2f4f15 ↩