대한민국 국민 묘사 합성 페르소나의 9Axes 평가 수행
들어가기 전,
실험의 전체 내용은 ShapeLayer/9axes-eval-using-nvidia-kr-persona를 참고하세요. 대부분의 내용은 이하에도 포함하고 있으나, 이 실험을 하게 된 계기, 개인적인 경험도 함께 포함되어 있으므로, 실험 보고서로써는 이 글은 부적절할 수 있습니다.
이 실험을 수행하게 되기까지
나는 우리나라에서 널리 쓰이는 간략화된 정치 군집 분류로는 호남권 지방의, 20대 남성 축에 속하는 조금 독특한 위치를 차지하고 있다.
때문에 주변으로부터 정치적인 이야기ー이 방면에서 사람들은 모두 자신의 진의를 밝히는 것을 꺼리기 때문에 대부분은 농담조로 들려오는 것이다.ー를 듣자면, ‘이 지역 사람이라면 OOO 뽑아야지’, ‘군대 나온 사람이라면 OOO 안뽑을 수 없지’, ‘우리들이 뽑을 사람은 OOO밖에 없어’ 라는 식의, 우리나라에서 각자의 군집이 가지고 있는 다소 편견어린 정치 스펙트럼을 전제로 한 이야기들을 어렵지 않게 만날 수 있다.
다만 내 의도와는 무관하게 내가 걸쳐있는 어떤 군집들은 서로 상극 관계에 있기도 하여, 꽤나 양극단의, 혹은 매우 다양성있는 견해들을 골고루 접할 수 있기도 하다. 그래서 더욱 정치적인 편견이나 견해를 갖기 힘든 위치에 있다고 생각하는데, 여기에 대한 연장선에서 나는 이러한 생각을 갖게 되었다.
우리나라의 양분된 정치 지형은 오늘날의 정치 담론이 거대 양당에 대한 지지로서 투영되었기 때문에 발생한 것이다. 거대 양당에 대한 이야기를 걷어낸다면, 각각의 사람들이 갖는 정치적인 견해는 양쪽으로 갈라지기보다 중도에 수렴할 것이다.
그래서 25년 전반기 〈분산시스템〉 교과목에서 데이터를 다루기만 하면 무엇이든 오케이라는 학기 성적 평가 프로젝트 과제에서, ‘이전 선거의 전국 투표 자료 데이터를 사용해, 각 선거구별 정치 스펙트럼을 산출하기’election-result-8values-spark를 주제로 설정해 실험을 수행한 바 있었다.
이 실험에서는 당시 정당과 후보들의 공약집, 정책 백서, 강령이나 언론 인터뷰 등을 모두 수집해, 다양한 모델의 LLM에게 각 정당에 대해 8values 평가를 수행하도록 하였다. 이들 모델이 평가한 값을 평균내어 각 정당마다 8values 값을 획득, 이것을 가중치로서 활용해 각 선거구별 투표 통계값에 가중합하여, 각 선거구별 정치 스펙트럼을 산출하였다.
하지만 캡스톤디자인과 병행하면서 이 학기의 교과목 모두 제대로 시간을 쏟을 수 없었고, 이 실험에서도 치명적인 오류가 있었다. (1) 우선 근본적인 문제로 LLM이라고 8values 평가가 제대로 수행된다고 보장하기 어려웠는데, 그 이전에 LLM을 통해 8values 평가를 수행하는 것 자체가 적절한지도 제대로 살펴보지 않았다. (2) 8values 평가가 관계한 학계에서 유용한 측정 도구로서 아마 인정받지 못할 것이라는 것도 내가 외면한 지점이었다.
그 외에 (3) 소수 정당, 단일 쟁점 정당, 혹은 정당의 특수한 위치를 이용하기 위한 목적으로 설립된 극단의 정당 등에서는 LLM에게 판단 자료로 제공할 데이터가 충분하지 않았다. 마지막으로 가장 부끄럽게 생각하는 부분인데, (4) 통계 처리 과정에서 지나치게 많은 오류가 있었다. 특히 평균을 내겠다는 요량으로, 지역구 대표와 비례대표 후보 투표, 보궐선거 투표까지 선거구가 같다면 모두 한 데 병합해서 평가를 수행했다. 그 바람에 결과가 얼마나 현실과 잘 맞아떨어지는가 여부와 무관하게 방법론에서 평가 자체를 신뢰 불가능하게 되었다고 생각하게 되었다.
또 최근에 엔비디아에서 100만건의 한국인을 묘사하는 페르소나 데이터셋을 공개한 적이 있다. 이 데이터셋은 다른 것보다 100만건이라는 양과, 엔비디아라는 조직에서 발표한 것이라는 점에서 많은 주목을 받았다.
마침 선거철을 앞두고 정치권에서 선거 주자를 막 고르기 시작한 시기였기 때문에, 이 데이터셋에서 페르소나 5천건을 추출해 모의 투표시켜보는 실험이 시도된 바 있었다. 이 실험에서는 눈에 띄는 편향이 다수 발견되었고, 또한 투입된 페르소나 데이터에서도 정치성향 필드가 부재하여, 페르소나 시뮬레이션이 여론조사 대체제가 될 수 없다고 결론내려졌다.
다만 이 실험 자체를 두고, LLM을 사용해 정치 성향을 평가하려고 시도하였다는 점에서, 앞서 과제로서 수행한 8values 평가 실험이 떠오르는 지점이 있었다. 따라서 앞서 수행한 8values 실험, 그리고 이 5천건 모의투표 실험을 보완하는 시도로서 이번 실험의 수행을 계획하게 되었다.
1. 도입
역사적으로 인간의 인격을 시뮬레이션하여 다양한 연구에 사용하려는 시도는 계속해서 있어왔다. 일라이자 효과(혹은 테오도르 신드롬)으로 더 널리 알려진 Weizenbaum, Joseph의 챗봇 Eliza(일라이자)는 심리치료사를 모방[4]했다. 일라이자의 개발 의도가 인격을 시뮬레이션 하는 것은 아니었으나, 일라이자와 대화를 주고 받은 사람들은 대화에 깊이 빠져들어 일라이자를 진짜 의사로 믿는 사례가 보고되었다.
이러한 인격 시뮬레이션은 비디오 게임《Grand Theft Auto》시리즈, 《The Sims》시리즈 등에서 플레이어가 인게임 환경과 상호작용할 수 있게 하는 도구로서, 인게임 NPC들의 행동과 대화에 제한적이게나마 결정론적 인격을 부여하는 형태로 활용되어왔다. 최근에는 대형 언어 모델(LLM)의 발전으로 《인조이》의 “스마트조이” 기능과 같이 결정론적 인격 대신 LLM에 인격을 부여하여 플레이어와의 상호작용에 활용하고 있다.
이들 비디오 게임에서의 활용 사례에서 보듯, LLM에 페르소나를 부여해 인격을 시뮬레이션하기도 하는데, 박준성 등의 연구에서 25개의 LLM 에이전트들을 두고 가상 마을에서 에이전트들 간 상호작용을 추적하여 사회적 네트워크를 분석한 사례가 있다.[5] 국내에서는 국가데이터처(구 통계청)의 MDIS 마이크로데이터를 LLM 페르소나 부여에 활용, 이렇게 페르소나를 부여한 모델에게 사회 현안을 질문, 답변을 생성하도록 함으로써, 일종의 여론 조사 시뮬레이션을 수행하게 하는 서비스가 등장하기도 하였다.[3]
2. 배경
근래에는 이에 그치지 않고 페르소나 부여가 실제로 생산성 향상에 도움이 된다는 주장이 등장하기도 했다. LLM에 작업을 지시하는데 있어 페르소나를 먼저 부여하고 원하는 바를 지시하면, LLM이 더 나은 결과를 낸다는 주장[6], 연구[7] 등이 널리 퍼지게 되어, LLM에 명령을 내릴 때 페르소나를 앞서 부여하는 것은 이제 일반화된 프롬프트 엔지니어링 기법이 되었다.
지금까지의 이러한 시도를 배경으로, 최근 엔비디아에서는 공공에 공개된 데이터를 합성하여, 대한민국 국민 페르소나 100만건을 대규모 데이터셋으로 공개하였다.[1] Jin은 이 데이터셋을 이용해 같이 오는 제9회 전국동시지방선거를 시뮬레이션 한 바 있었다.[2]
이 실험에서는 Jin의 시도와 비슷하게, 교과과정 상 과제로서 이전 선거의 지역별 후보자/정당 투표 통계값과 LLM을 통해 수행한 각 후보자/정당별 8values 평가(LLM 8values 평가)를 동원해 지역별 정치 성향을 산출하려는 시도를 한 바 있었다. 하지만 LLM 8values 평가의 변동성이 커 신뢰하기 어려웠고, 통계와 무관한 교과과목의 과제로서 수행하면서, 통계 산출에 큰 오류를 범하기도 하여, 개선이 필요하다고 판단하게 되었다.
그래서 이 리포지토리에서는 엔비디아의 대한민국 국민 페르소나 데이터셋을 사용하여 LLM에 페르소나를 부여, 216개 문항에 대해 9Axes 평가를 수행한 결과, 그리고 결과를 해석하고 일련의 과정에서 발견한 한계점들을 서술하려고 한다.
3. 방법론 및 실험
실험은 엔비디아 대한민국 국민 페르소나 데이터셋에서 각 페르소나 데이터를 불러와, 각 페르소나 데이터에 대해 9Axes 평가 문항 216개에 대해 LLM에게 답변을 생성하도록 하는 방식으로 수행되었다. 페르소나 데이터는 식별자uuid를 제외한 25개 필드1를 누락 없이 모두 프롬프트에 적용하였다. 9Axes 평가 문항은 LLM의 컨텍스트 길이 제한을 고려하여 질문을 배치 처리해 수행했다. 각 질문에 대한 답변은 1~5 사이의 정수로 표현된 JSON 리스트로 반환하도록 하였으며, 답변이 올바른 형식으로 반환될 때까지 질문을 반복하도록 하였다.
실험은 Google의 Gemma 4 31Bgoogle/gemma-4-31b-it를 사용하여 질문 배치 크기 $N_Q = 50$ 으로 각 페르소나 데이터에 대해 216개 문항을 5개 배치로 나누어 수행하였다. 질문 배치 크기 $N_Q$ 를 $50$ 을 넘겨 $60$, $75$, $100$ 로 증가시켜서도 실험을 수행해보았으나, 반환하는 JSON 리스트의 길이가 $N_Q$ 보다 작거나 커지는 문제가 관찰, $N_Q$ 가 증가함에 따라 이 문제가 더 빈번하게 발생하는 경향이 관찰되었다. 이에 Gemma 4 31B에 대해서 $N_Q > 50$ 인 쿼리는 신뢰성이 크게 훼손된다고 판단하였다. 이들 문제의 원인은 모델에 프롬프트를 통해 추론 내용을 제외하고 순수 JSON 정수 리스트 값을 반환하도록 지시하였기 때문에, 추론을 획득할 수 없어 원인을 분석할 수 없었다. 관련해서는 이어지는 <결과와 한계>에서 자세히 서술하였다.
3.1. 9Axes 평가 지표
9Axes는 각 축마다, 축 상에서 대립하는 두 개 이념을 지지하는 각 12개 문항, 총 24개의 문항에 대해 각 문항의 응답값을 가중합하여 9개 축의 점수를 산출한다. 이들 이념을 지지하는 12개 문항은 문항별로 이념을 지지하는 강도가 상이하지만, 평가에는 반영되지 않는다. 따라서 각 문항에 대한 가중치는 문항이 얼마나 개별 이념을 지지하는지와는 관계없이 방향성만을 반영하도록 부여된다. 질문 $q$ 의 방향성 가중치 $d_q$ 와, $q$ 에 대한 응답 $a_q$ 에 대해 각 축 $k$ 의 점수 $S_k \in [-50, 50]$ 는 다음과 같이 계산된다. -50과 50은 각 대립축의 극단, 0은 중립을 나타낸다.
\[a'_q = a_q - 3 \quad (a_q \in \{1, 2, 3, 4, 5\})\] \[S_k = \sum_{q \in Q_k} d_q a'_q \quad (d_q \in \{-1, 1\})\]혹은 대립축 $k$ 의 한 극단에 얼마나 동의하는지에 대해 $S’_k$ 와 같이 표현할 수 있다.
\[S'_k = S_k + 50 \quad (S'_k \in [0, 100])\]9Axes 평가에서 대상의 이데올로기 판별에는 9개 축을 전부 사용하지 않고, 평등-시장 축, 민주-권위 축, 국제주의-고립주의 축, 진보-전통 축을 사용하여, 사전에 샘플링된 이데올로기 중 최근접 이웃을 선택한다. $e_I, g_I, d_I, s_I$는 각각 이데올로기 $I$ 의 Equality, Democratic, Global, Progressive 기준값이다.2
\[D(I)=|e_I-S'_{\mathrm{Equality}}|^2 + |g_I-S'_{\mathrm{Democratic}}|^2 + |d_I-S'_{\mathrm{Global}}|^{1.73856063} + |s_I-S'_{\mathrm{Progressive}}|^{1.73856063}\] \[\hat I = \arg\min_I D(I)\]4. 결과와 한계
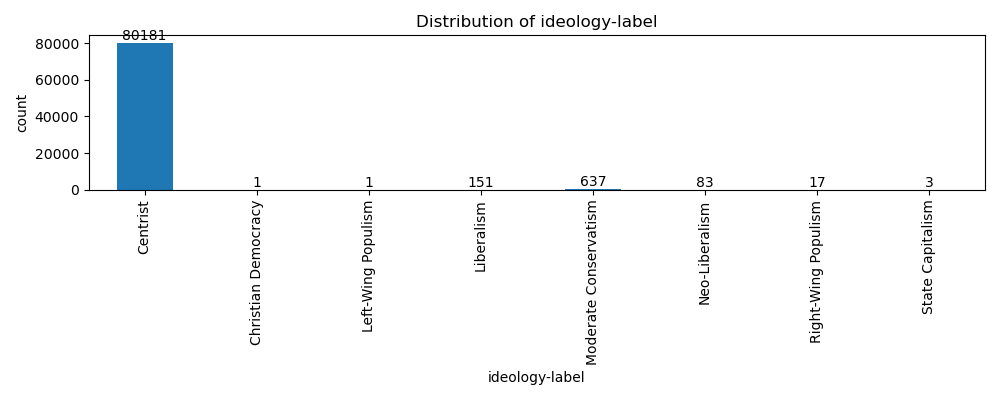
실험은 전체 페르소나 데이터 100만건 중 81074건에 대해 수행되었다. 답변의 개별적인 양상은 “3. 중립/모름”이 아니라 “1. 적극 찬성”부터 “5. 적극 반대”까지 다양하게 나타났으나, 대부분의 페르소나가 9Axes 평가에서 중립적(Centrist) 평가를 받는 경향이 관찰되었다.
4.1. 결과 상세
앞서 방법론에서 살펴본 $S’_k \in [0, 100]$ 는 대립축의 한쪽 극단에 대해 얼마나 동의하는지 정도를 표현하는 지표였다. 각 대립축의 점수(이데올로기 동의 점수)는 0에서 100 사이의 값으로 표현되며, 100은 축의 한쪽 극단을, 0은 반대쪽 극단으로 이해할 수 있다.
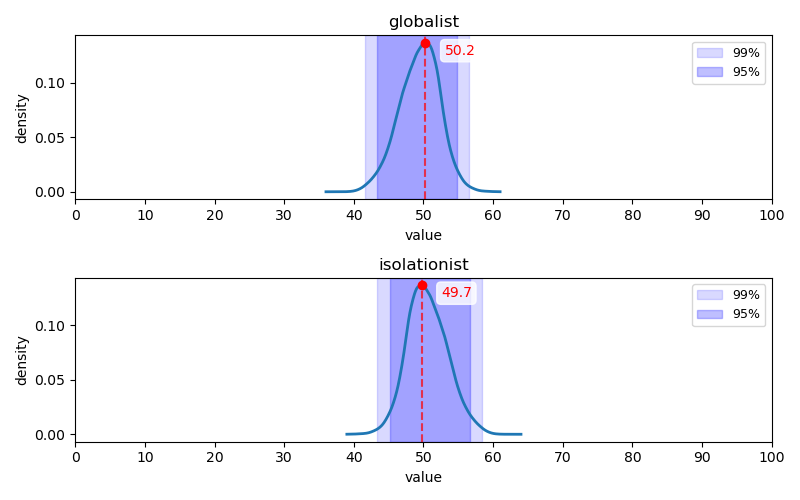
모든 대립축에서 페르소나의 각 대립축별 이데올로기 동의 점수의 최빈값은 중간 지점이라고 할 수 있는 $[40, 60]$ 을 넘지 않았다. 또한 대부분의 대립축에서 95% 상당의 페르소나의 이데올로기 동의 점수가 $[40, 60]$ 구간에 위치하는 경향이 관찰되었다.
아래의 점수 분포는 각 대립축별로 페르소나의 이데올로기 점수의 분포를 나타낸 것이다.
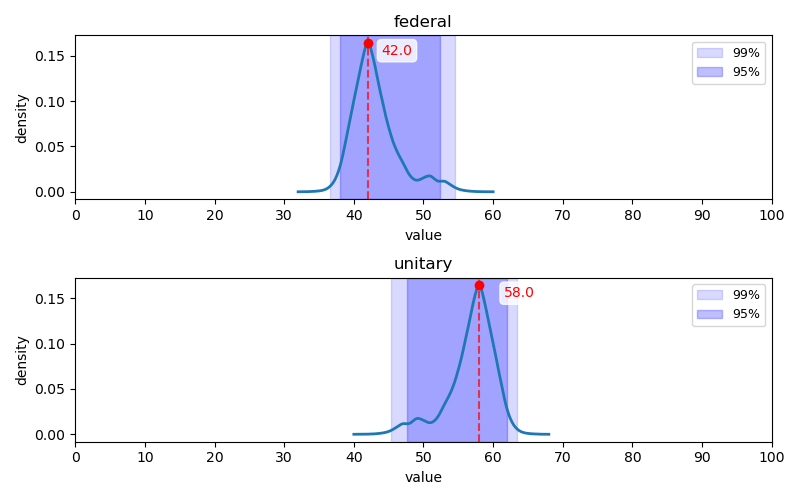
연방주의-단일주의 축
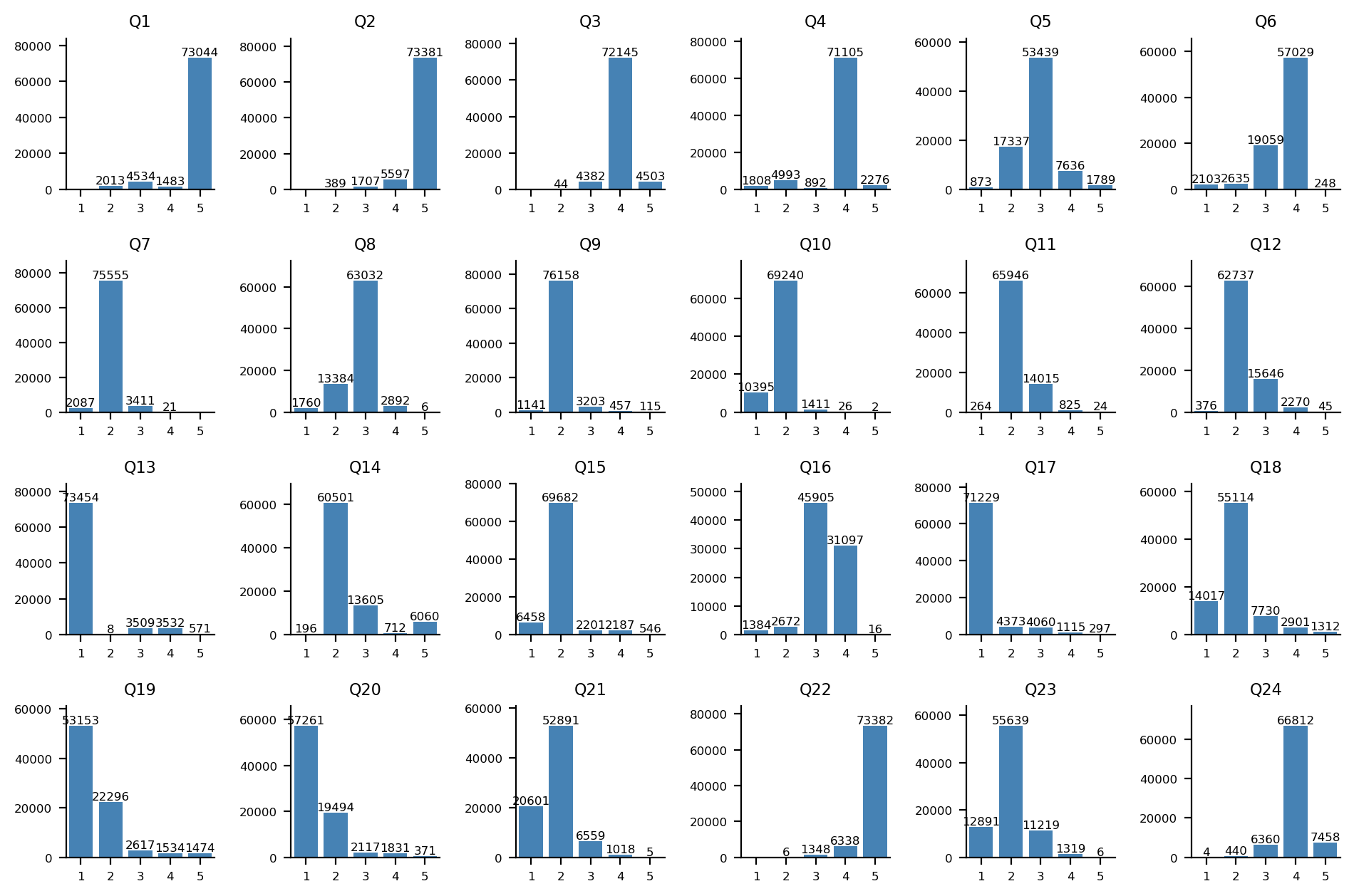
Q1-Q24 문항에 대한 답변 분포: Q1-Q12(위 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 연방제 지지, Q13-Q24(아래 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 단일주의 지지
연방주의-단일주의 축에서는 다른 축에 비해 상대적으로 한쪽으로 치우친 분포가 관찰되었다. <평가 척도의 한계>에서 언급하였듯, 대한민국의 지방자치체는 미국의 주(State)와는 다르기 때문에, 이 축의 문항들은 단일주의에 치우친 답변이 생성되는 경향이 있는 것으로 보인다. 하지만 대한민국은 연방제를 적용하기에 적절한 국가로 보기는 어렵고, 이와 관련하여 사회에서는 일말의 논의도 제안되지 않고 있기 때문에 실제 인물들을 대상으로 평가하더라도 이와 상이한 분포가 관찰될 가능성은 낮아 보인다.
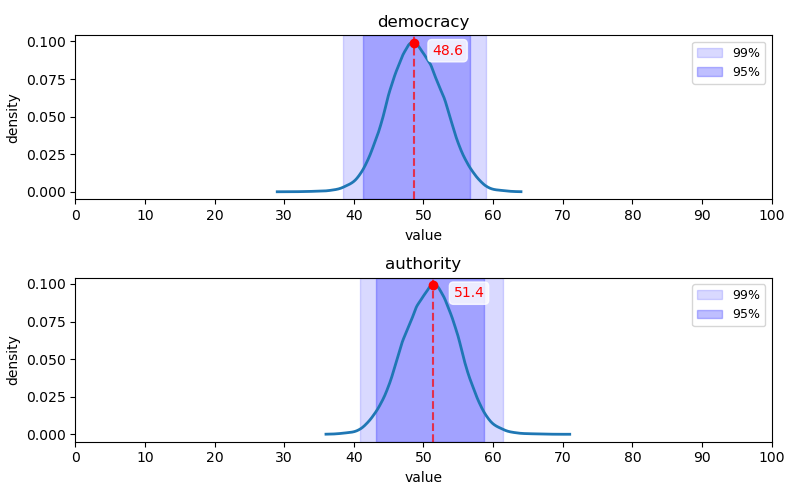
민주주의-권위주의 축
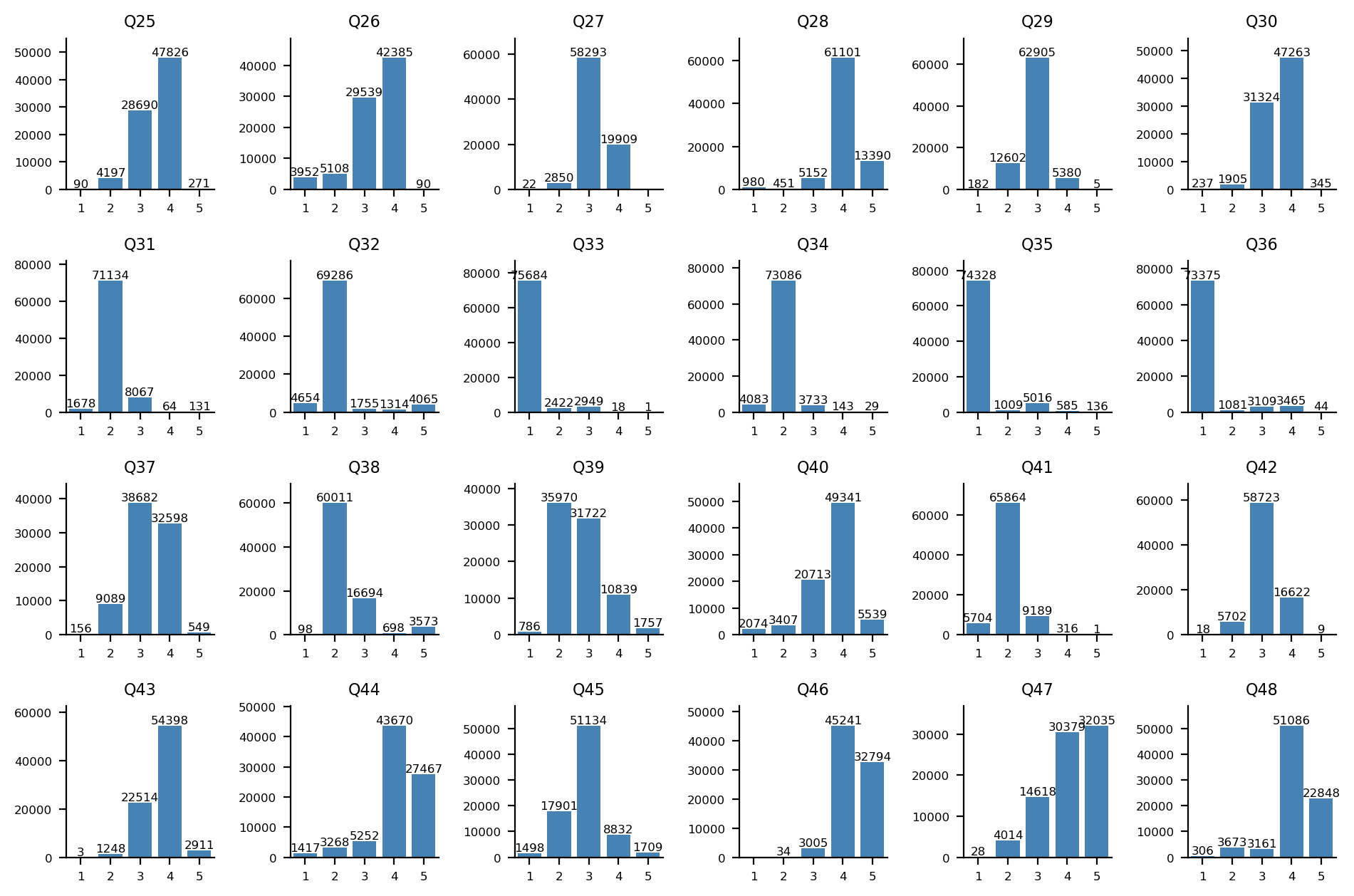
Q25-Q48 문항에 대한 답변 분포: Q25-Q36(위 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 민주주의 지지, Q37-Q48(아래 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 권위주의 지지
국제주의-고립주의 축
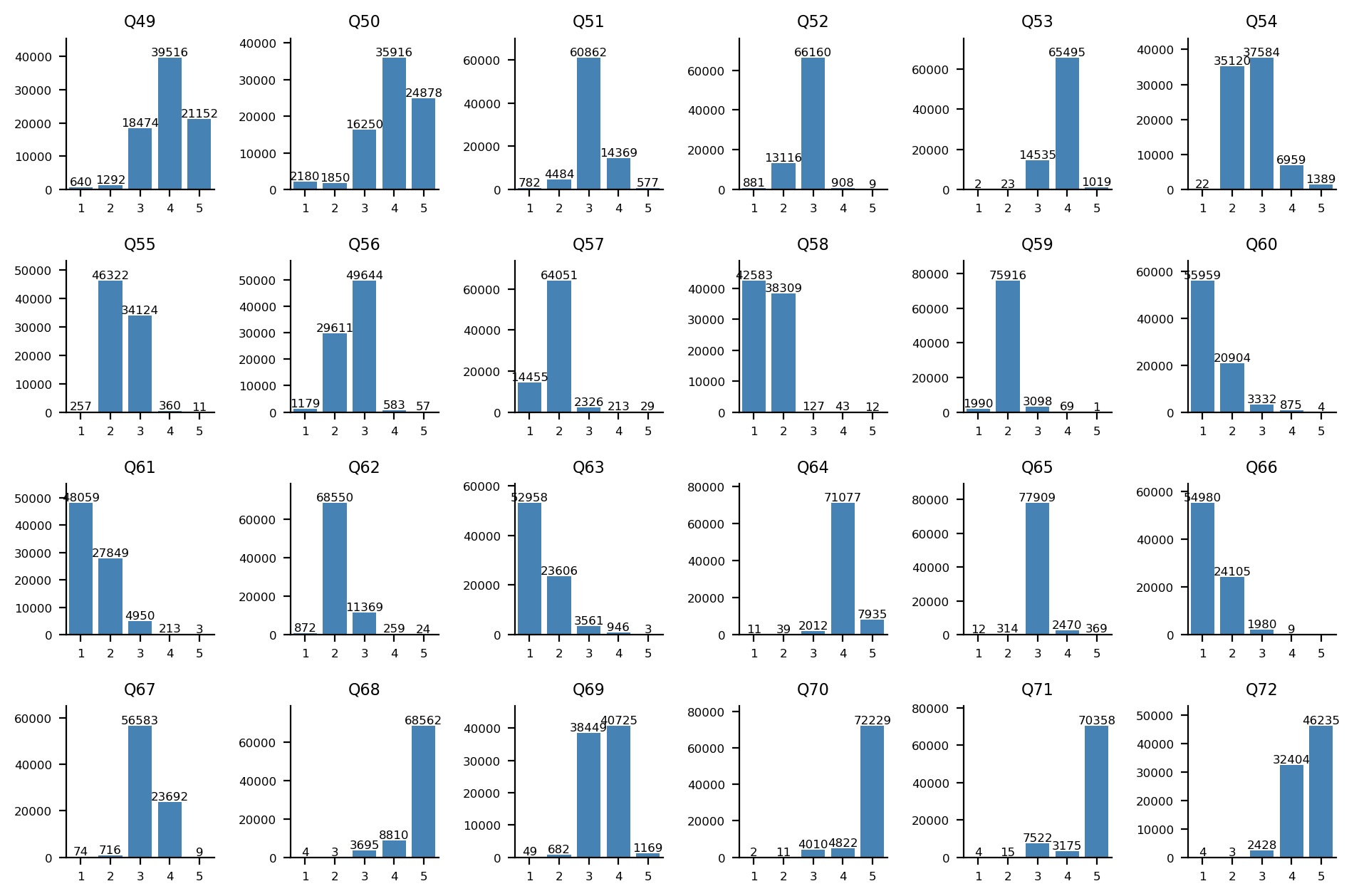
Q49-Q72 문항에 대한 답변 분포: Q49-Q60(위 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 국제주의 지지, Q61-Q72(아래 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 고립주의 지지
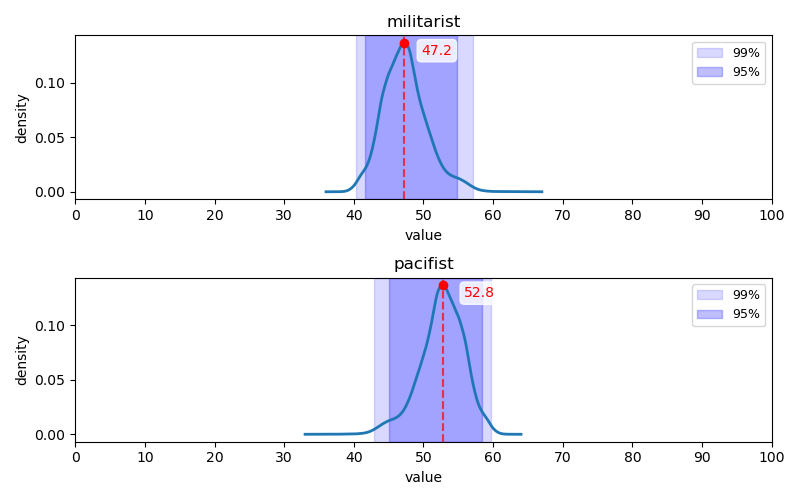
군국주의-평화주의 축
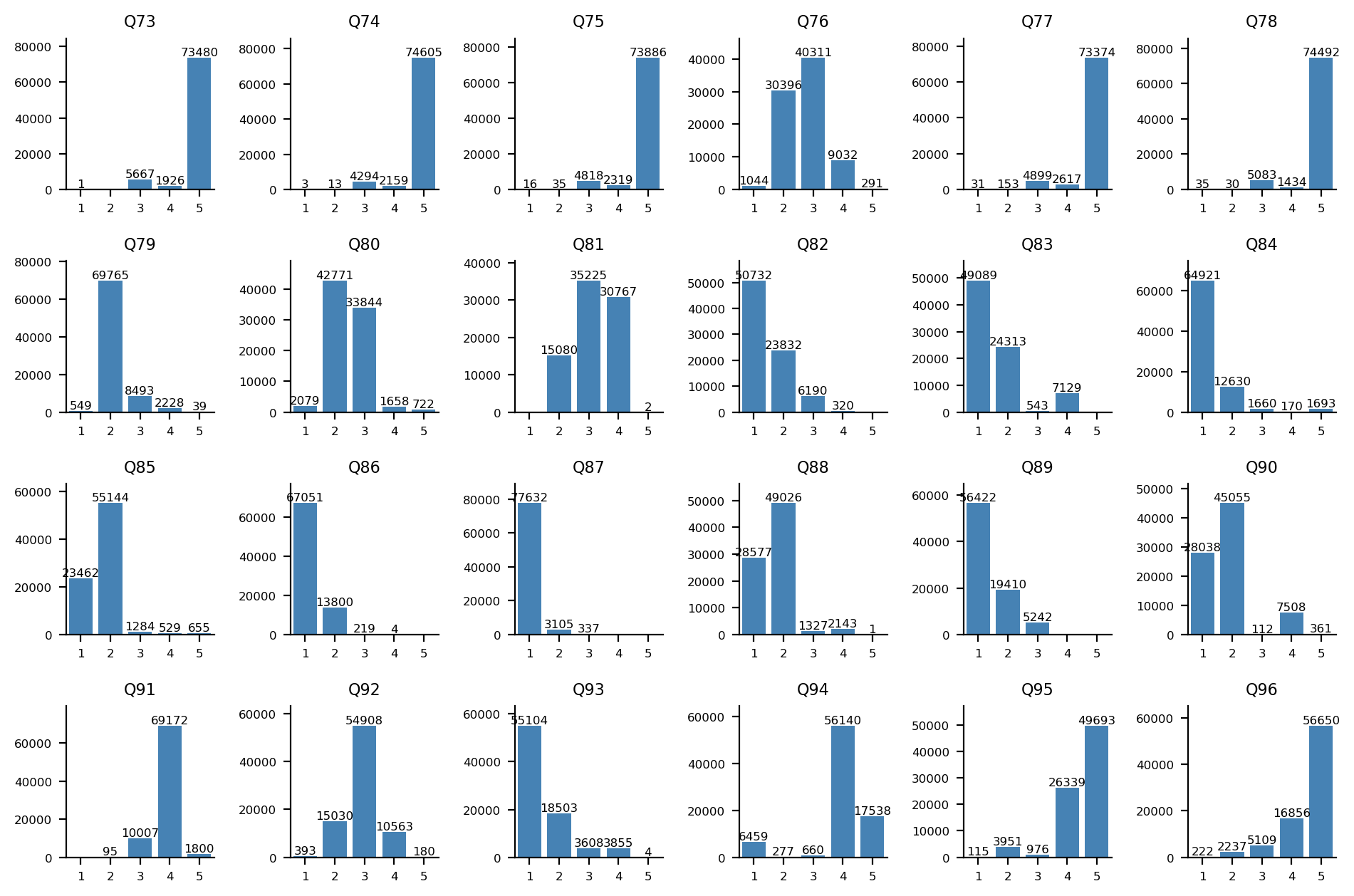
Q73-Q96 문항에 대한 답변 분포: Q73-Q84(위 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 군국주의 지지, Q85-Q96(아래 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 평화주의 지지
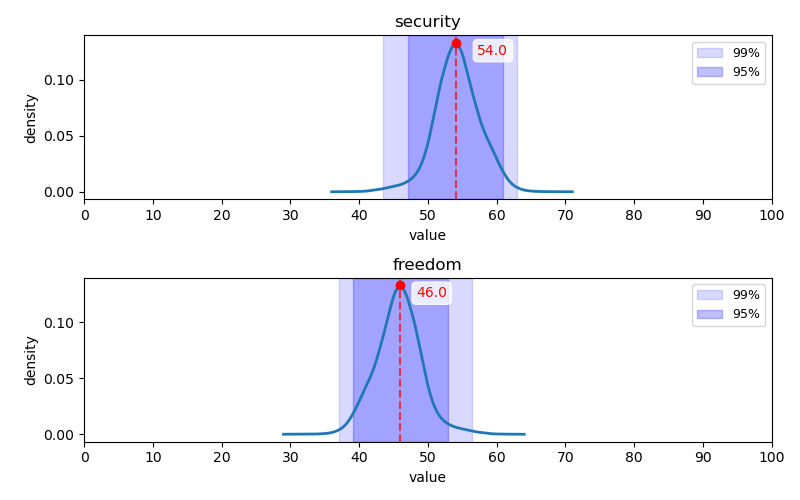
안보주의-자유주의 축
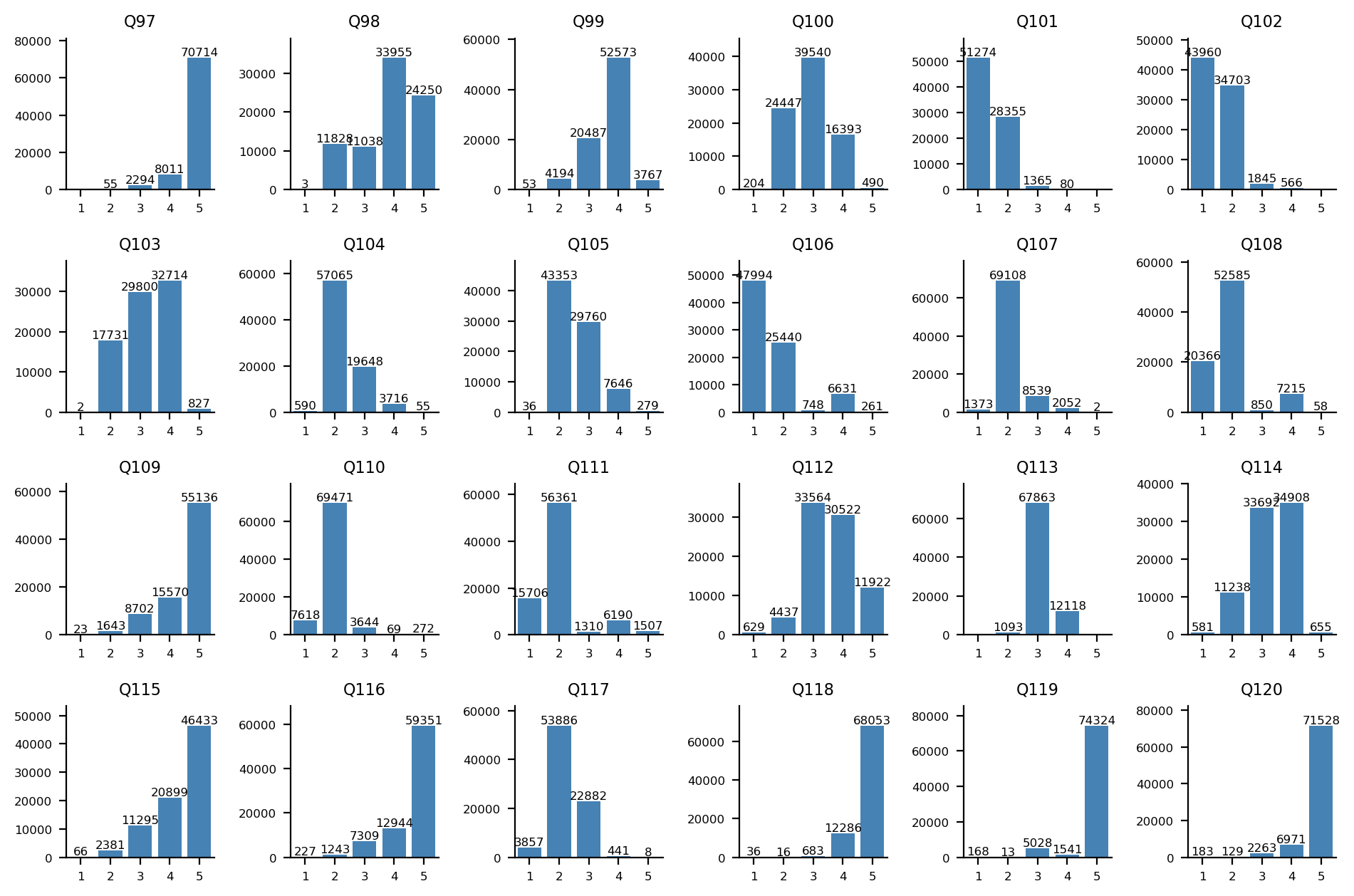
Q97-Q120 문항에 대한 답변 분포: Q97-Q108(위 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 안보주의 지지, Q109-Q120(아래 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 자유주의 지지
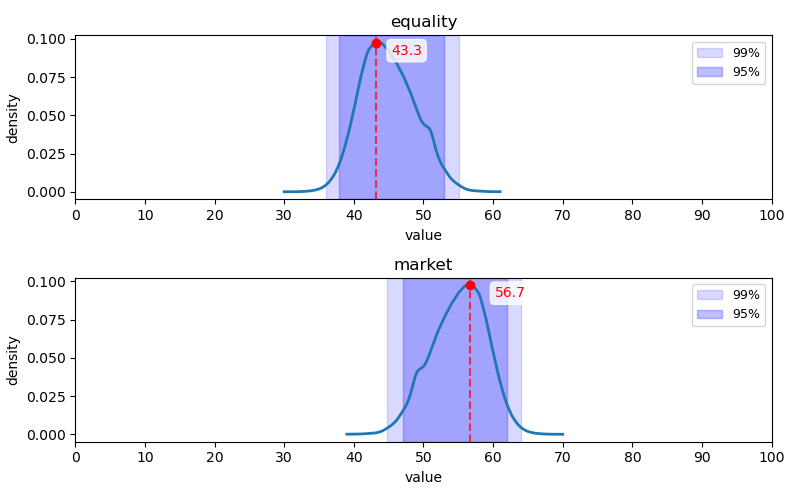
평등주의-시장주의 축
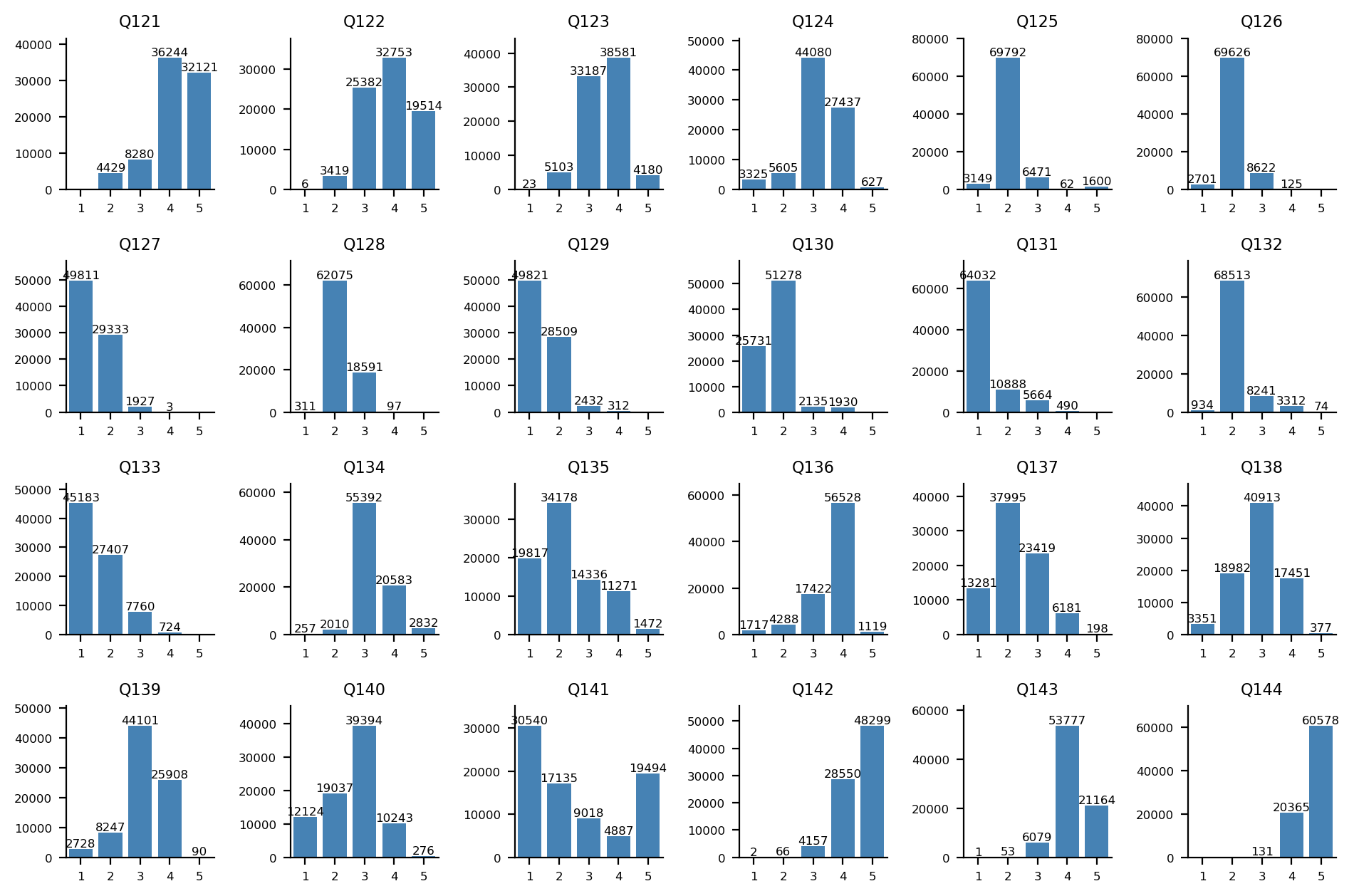
Q121-Q144 문항에 대한 답변 분포: Q121-Q132(위 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 평등주의 지지, Q133-Q144(아래 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 시장주의 지지
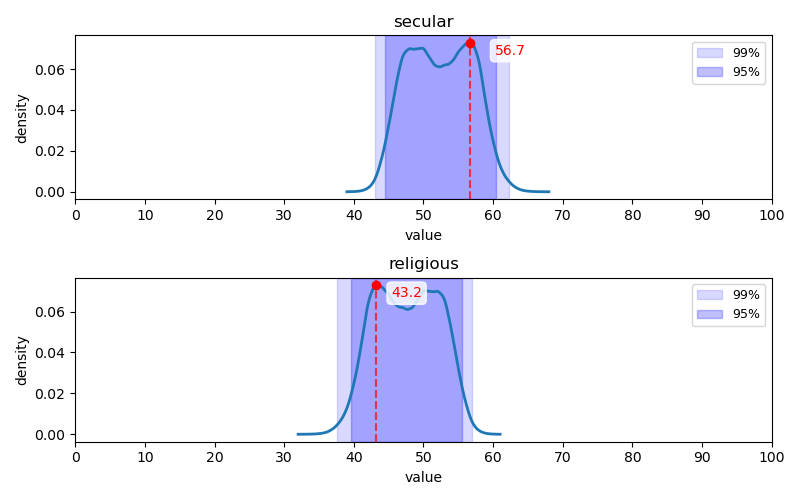
세속주의-종교주의 축
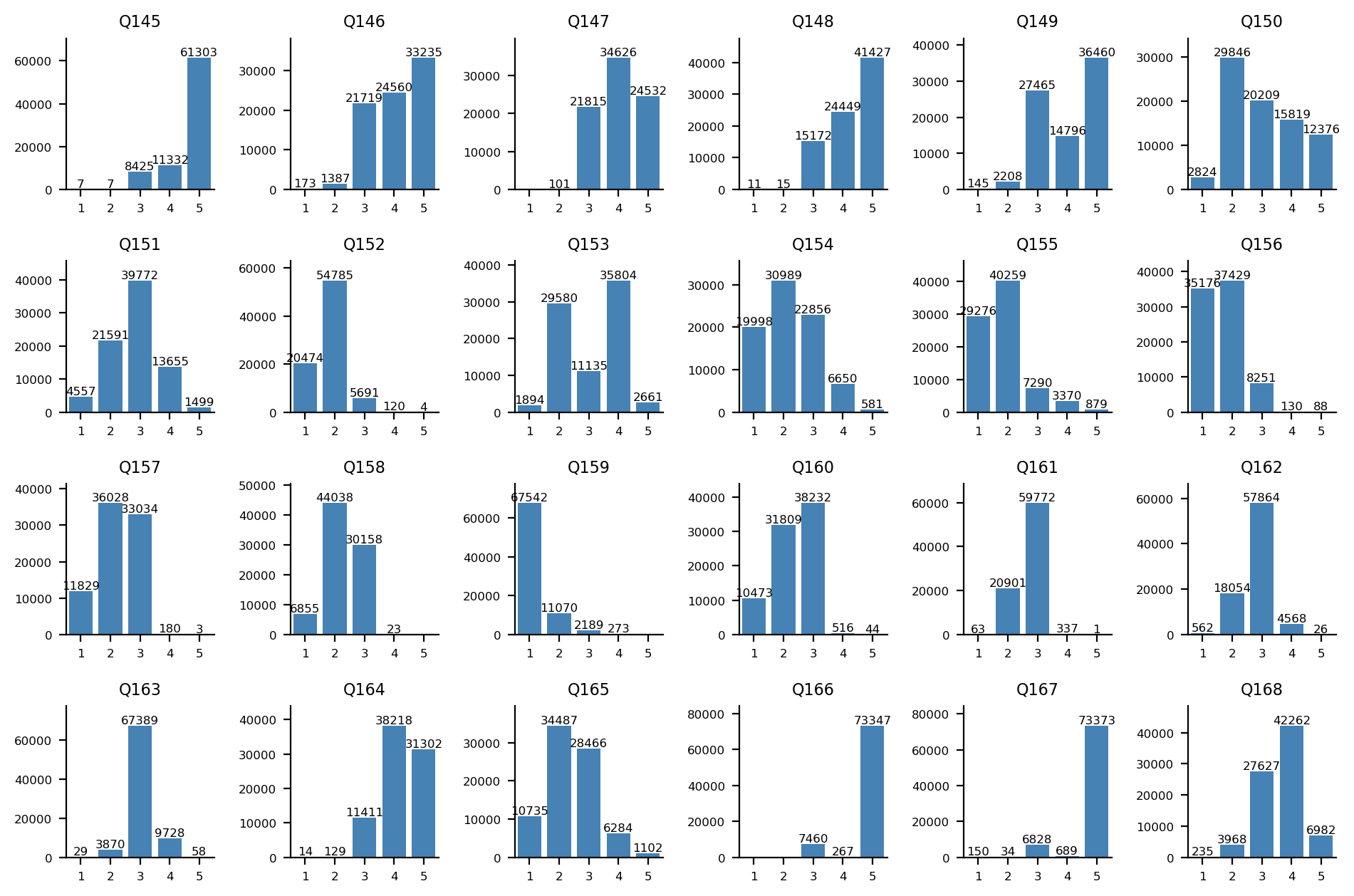
Q145-Q168 문항에 대한 답변 분포: Q145-Q156(위 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 세속주의 지지, Q157-Q168(아래 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 종교주의 지지
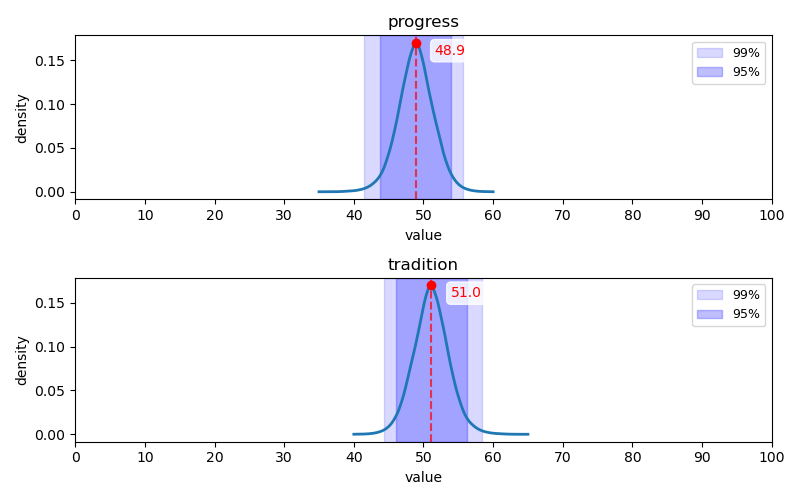
진보주의-전통주의 축
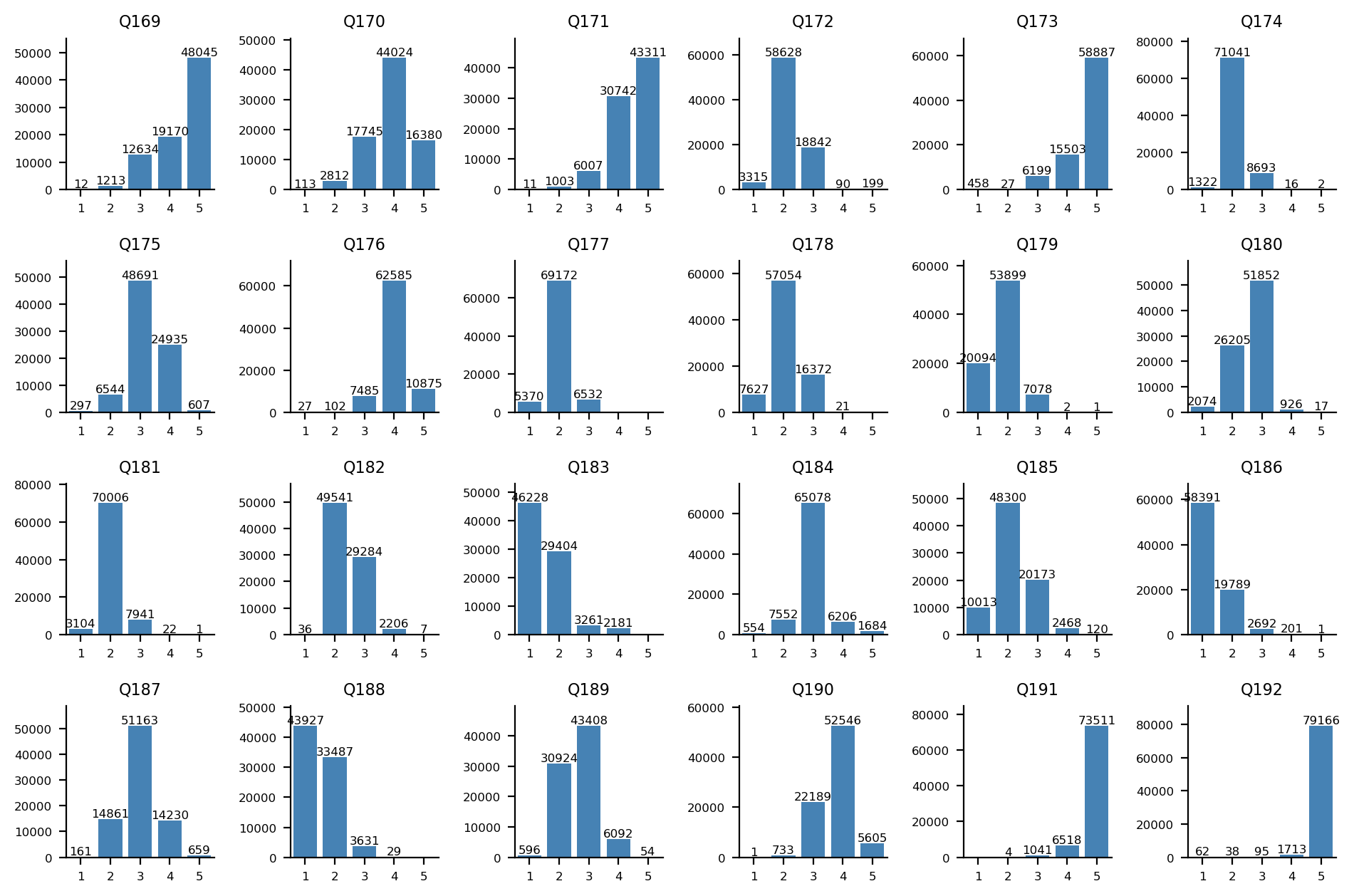
Q169-Q192 문항에 대한 답변 분포: Q169-Q180(위 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 진보주의 지지, Q181-Q192(아래 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 전통주의 지지
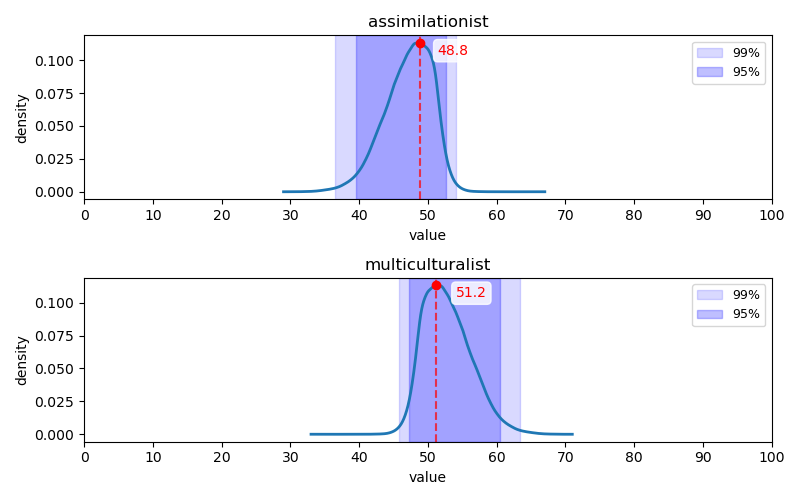 동화주의-다문화주의 축
동화주의-다문화주의 축
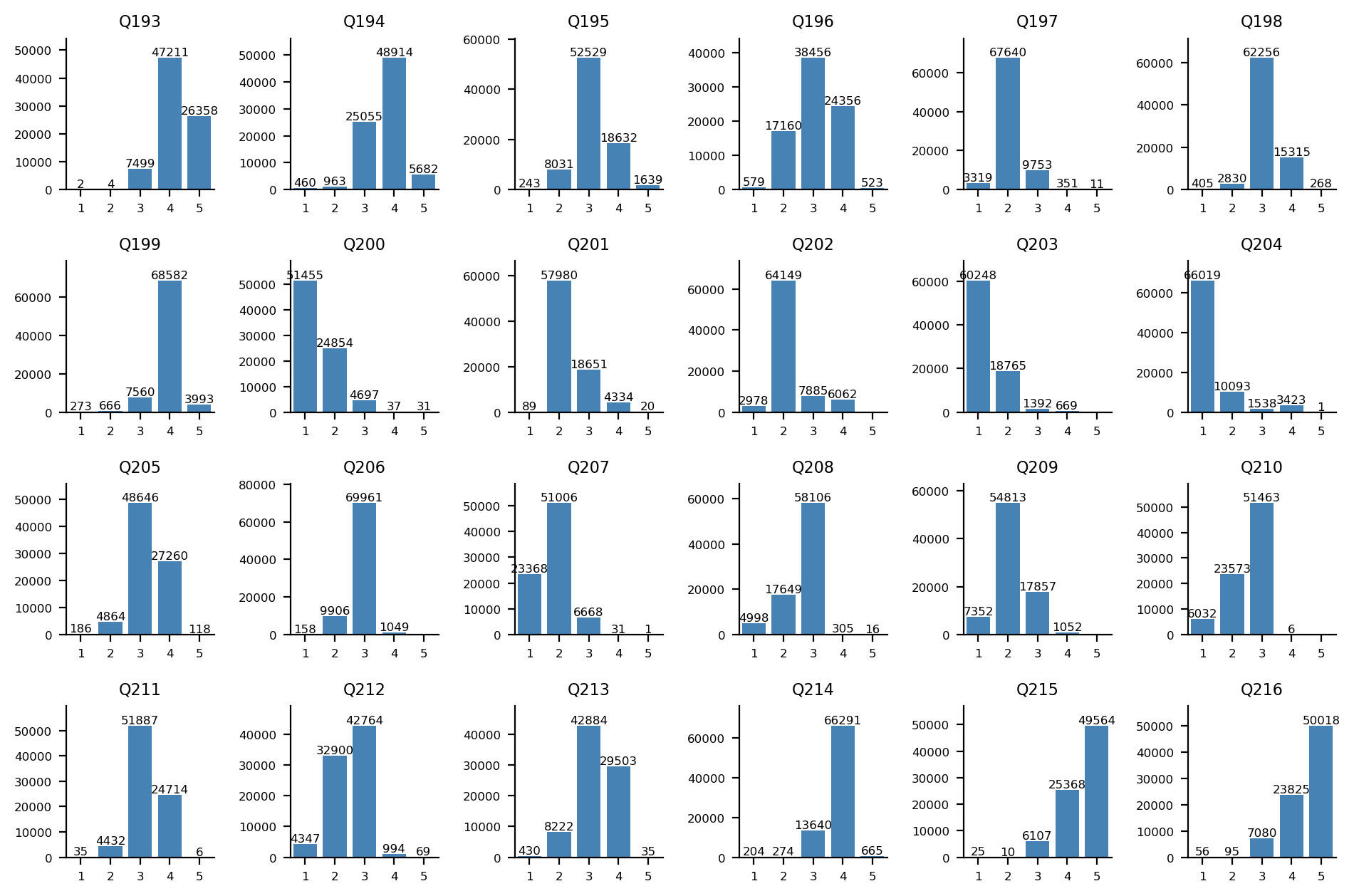
Q193-Q216 문항에 대한 답변 분포: Q193-Q204(위 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 동화주의 지지, Q205-Q216(아래 2개 행)는 1, 2번(히스토그램 상 좌측) 항목이 다문화주의 지지
4.2. 실험의 한계
쿼리의 한계
이 실험에서는 쿼리 결과를 결정적으로 획득하고 출력 토큰을 절약하기 위해, 정수로 이루어진 JSON 리스트만을 답변으로 반환하도록 하였다. 이 덕분에 LLM의 답변을 결정적으로 획득하고 시간, 비용 측면에서 효율성을 획득할 수 있었다.
하지만 동시에 LLM이 구체적으로 어떠한 사유로 각 질문에 대해 어떠한 답변을 선택했는지 정보를 획득할 수 없었다. LLM의 답변 원리는 완전히 블랙박스가 되었다. 따라서 개별 답변이 잘못 답변된 것이거나, 다른 질문 항목과 순서가 섞였는지, LLM이 질문을 제대로 이해했는지, 혹은 페르소나 데이터의 어떠한 특성이 답변에 영향을 미쳤는지 등을 분석할 수 없었다. 따라서 실험 결과를 제한적으로 해석하거나, 개별 답안의 오류를 압도하기 위해 전체 평가 데이터의 경향성을 판단하는 수준에서 해석할 수밖에 없었다.
페르소나의 한계
하지만 결과에서 보이듯 사실상 모든 페르소나가 중립적(Centrist)인 것으로 평가되어, 가치있는 평가를 획득했다고 하기 어렵게 되었다. 결론 내기 조심스러운 수준으로 일관되게 중립적으로 평가되었으므로, 전체 평가 데이터의 경향성을 분석하는 것도 한계가 있었다.
페르소나 데이터셋은 개별 페르소나 데이터의 인격이나 정치적 특성, 행동 원리, 가치판단 근거 등이 명시적으로, 혹은 두드러지게 나타나지 않았다. 때문에 LLM은 페르소나가 표현하려는 인물상의 정치적 특성을 재현하는데 제한이 있었다.
실험적으로 유정례(c75fcee7523a4317851cfbecc85046a3) 페르소나에 대해 Q101-Q150 문항에 답변을 지시하면서 추론을 함께 반환하도록 하였는데, LLM은 주어진 페르소나를 심층적으로 설명하지 못하고 단편적인 정보들을 나열하는 수준에서 페르소나를 해석하여 답변을 생성하였다. 다음은 이 페르소나가 법과 질서, 정부의 권한 부분에 대해 답변하면서 생성한 추론이다. (추론 본문의 Q1-Q20 문항은 배치 처리로 질문 번호가 재정렬된 것으로, 실제로는 Q101-Q120 문항에 해당한다.)
1
2
3
4
5
6
7
유정례 씨는 연간 예산을 1원 단위까지 맞추는 꼼꼼함과 전문성을 가진 마케팅 전문가입니다. 따라서
사회의 기본 틀이 되는 법과 질서의 중요성을 높게 평가하며(Q1(Q101), Q2(Q102), Q7(Q107
), Q8(Q108)), 현실적인 안전을 위해 어느 정도의 통제는 필요하다고 생각합니다(Q6(Q106)).
하지만 동시에 미혼으로서 독립적인 삶의 공간과 자신만의 리듬을 매우 소중히 여기는 성격이기에, 정
부가 개인의 사생활이나 통신에 과도하게 개입하는 것에는 거부감을 느낍니다(Q3(Q103), Q11(Q11
1)). 인문학적 소양을 갖추고 있어 맹목적인 권위보다는 합리적인 의문을 제기하는 태도를 지향합니
다(Q14(Q114)).
Q101-Q150 문항에 대한 추론 전체 결과는 부록의 <유정례(c75fcee7523a4317851cfbecc85046a3) 페르소나 쿼리의 Reasoning>에 수록하였다.
이와 같이 개별 페르소나 데이터에 인격, 정치적 특성, 행동 원리, 가치판단 근거 등이 풍부하게 포함되지 않았기 때문에, LLM은 표면적이고 단편적인 정보들을 나열하는 수준에서 답변을 생성하였다. 따라서 이 실험을 개선하려면 더욱 풍부하고 심층적인 페르소나 데이터가 필요할 것으로 보인다.
평가 척도의 한계
그 외에 이번 결과에 결정적인 영향을 미쳤을 것으로는 보이지 않으나, 평가 척도로 사용한 9Axes가 대한민국 상황에 적절한 평가 척도인지 여부에 대해서도 고려해보아야 한다.
9Axes는 자기 평가 도구로서 널리 퍼졌으나, 엄격한 신뢰성과 타당성을 갖추고 있지는 않다. 과학적으로 검증된 평가 척도가 아니고, 학계에 의해 제안된 것이 아니므로, 9Axes 자체가 개인이나 집단의 정치적 성향을 정확히 측정할 수 있는 도구라고 보기는 어렵다.
또한 9Axes 평가 문항은 미국의 정치 상황에 근거하여 작성되어 대한민국의 상황에서는 적절하다고 보기 어렵다. 구체적으로 Q3, Q4, Q19는 주(State)를 전제한 문항으으로, 이들 문항은 대한민국의 지방자치단체를 주에 대입하여 해석하기 어렵다. 또한 대한민국의 종교 분포, 종교별 호감도 등을 고려할 때 세속-종교(Secular-Religious) 축의 세속국가, 종교국가의 대립 구도는 전세계 국가 범위에서 대한민국을 설명하려는 것이 아닌 이상, 대한민국의 상황에서는 적절하지 않은 것으로 보인다.
평가 과정의 한계
LLM의 답변은 매 시도마다 다소의 변동성이 존재한다. 따라서 동일한 페르소나 데이터에 대해 동일한 질문을 여러 번 반복하여 개별 답변의 신뢰성을 획득하거나, 다른 LLM 모델을 사용하여 답변의 추이를 확인하거나, 이들 답변의 분포를 확인하여 답변이 사용 가능한 수준인지 판단해보았어야 했다. 하지만 시간과 비용의 제약으로 반복/변형 실험을 수행하지 못했다.
실험 설계 과정에서는 이 변동성을 국소적일 것으로 예단하여 반복 과정을 고려하지 않았다. 실험 과정에서 충분히 많은 페르소나 데이터에 대해서 평가를 수행한다면, 이들 개별 답변의 오류를 압도할 수 있을 것으로 생각했다.
하지만 실제로 이 변동성을 압도할 수 있었는지, 답변이 신뢰 가능한지 판단할 실체적 근거를 마련하지 못했다. 반복 실험이 모든 페르소나가 중립적으로 평가되는 결과를 바꾸지는 않았을 것으로는 보이지만, 개별 답변의 신뢰성을 확보하려는 노력을 하지 않았다는 점에서 반성해야 하겠다.
5. 결론
이번 실험은 엔비디아 대한민국 국민 페르소나 데이터셋을 사용하여 오는 지방선거를 시뮬레이션한 Jin의 시도[2]를 보충할 수 있으리라는 기대를 가지고 수행하였다.
하지만 대부분의 페르소나가 9Axes 평가에서 중립적(Centrist)인 것으로 평가되어, 가치있는 평가를 획득한 실험이었다고 보기는 어렵게 되었다. 실험 과정에서 LLM의 추론 과정을 적극적으로 해석하려고 하지 않고 블랙박스 상태로 두어, 이러한 결과가 나타난 원인 역시 충분히 분석할 수는 없었다.
이 원인을 파악하기 위해 제한적으로 추론을 생성하도록 한 시도에서는 LLM이 페르소나 데이터의 단편적인 정보들을 나열하는 수준에서 추론하는 것을 관찰할 수 있었다. 또한 LLM에게 페르소나가 표현하려는 인물상의 정치적 특성을 재현하기에는, 페르소나 데이터셋이 개별 페르소나 데이터의 인격이나 정치적 특성, 행동 원리, 가치판단 근거 등이 명시적으로, 혹은 두드러지게 나타나지 않았음을 추정할 수 있었다. 다만 마땅한 대조군이 없고, 반복 실험이 부재하여, 이러한 추정 역시 강한 인과를 갖는다고 보기는 어렵다.
따라서 이 실험을 개선하려면 더욱 풍부하고 심층적인 페르소나 데이터, 더욱 심층적으로 추론하는 인공지능 모델, 혹은 양자 모두가 필요할 것으로 보인다. 또한 비슷한 수준에서 시도한 다른 실험들에 대해서도 이와 유사한 경향이 관찰되는지 유의하여 살펴보아야 하며, 비슷한 규모로 반복 실험을 수행하여 이 실험에서 획득한 값이 신뢰 가능한지 판단해보아야 할 것으로 보인다.
부록
ShapeLayer/9axes-eval-using-nvidia-kr-persona 참조
References
[1] Kim et al. “Nemotron-Personas-Korea: Synthetic Personas Aligned to Real-World Distributions for Korea” 2026. https://huggingface.co/datasets/nvidia/Nemotron-Personas-Korea
[2] Jin “Athena” 2026. https://github.com/Kimchikilla/Athena
[3] ManyPerson. https://manyperson.com
[4] Weizenbaum, Joseph. “ELIZA—a computer program for the study of natural language communication between man and machine.” Communications of the ACM 9.1 (1966): 36-45.
[5] Park, Joon Sung, et al. “Generative agents: Interactive simulacra of human behavior.” Proceedings of the 36th annual acm symposium on user interface software and technology. 2023.
[6] stunspot, “On Persona Prompting” https://medium.com/@stunspot/on-persona-prompting-8c37e8b2f58c
[7] De Araujo, Pedro Henrique Luz, et al. “Principled personas: Defining and measuring the intended effects of persona prompting on task performance.” Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025.
professional_persona,sports_persona,arts_persona,travel_persona,culinary_persona,family_persona,persona,cultural_background,skills_and_expertise,skills_and_expertise_list,hobbies_and_interests,hobbies_and_interests_list,career_goals_and_ambitions,sex,age,marital_status,military_status,family_type,housing_type,education_level,bachelors_field,occupation,district,province,country↩이데올로기 $I$ 의 목록은 부록의 <9Axes의 이데올로기 샘플 목록>을 참조 ↩