26년 3월 AI_TOP_100 (CAMPUS) 예선 참가자 후기
직접 코드를 작성하는 것만이 진짜 프로그래밍이라고 주장하는 일종의 원리주의자였는데 이런 대회에 나가게 될 줄은 상상치도 못했다. 지난 얼마간의 경험이 나를 바꿔놓은 것 같다.
대회 준비
하지만 원리주의자라고 주장한 것 치고는 이번 대회에 꽤 많은 AI 모델과 공급자를 사용했다.
- Poe: 주력으로 사용하는 AI 리셀러다. 꽤 초반에 서비스가 시작되어, 지금은 경로의존성 때문에 계속 사용하고 있다.
- GitHub Copilot: 정말 프로그래밍에 파인튜닝한 것인지, 프로그래밍 성능에 있어 개선되었다고 느껴지는 것이 있어 프로그래밍 작업에 주로 사용하고 있다.
Cerebras: LLM 모델을 하드웨어로 구현해 토큰을 고속 출력하는 프로바이더이다. 이 대회에서 사용할 일이 많을 것 같아서, 따로 크레딧을 구매해두었다.
(구매 후 알게 된 것으로는, OpenAI와 협업을 시작하면서 GPT-5.3-Codex-Spark라는 모델을 통해 비슷한 토큰 생성 속도를 이용할 수 있다는 것이었다.)
- 타임리GPT: 학교에서 계약한 AI리셀러다.
이들 공급자의 모델을 각각 Visual Studio Code(Github Copilot, Kilo Code 익스텐션), OpenClaw, 각 공급자가 제공하는 채팅 인터페이스를 통해 교차해 사용했다.

대략적으로 위와 같이 구성하고, Poe, OpenRouter, Cerebras를 Kilo Code 익스텐션과 OpenClaw에 교차 등록했다. OpenClaw Gateway 수단은 디스코드와 Web UI였다.
OpenClaw와 주 기기(편의상 호스트로 명칭) 사이에 SMB 설정을 잡아놓았지만, 파일 공유는 주로 git을 사용했다. 동시에 같은 파일을 수정하게 될 지도 모르고, 그 때문에 모델이 형성한 컨텍스트와 실제 파일의 콘텐츠가 달라지는 것보다는, 커밋 단위로 파일을 동기화하는 편이 낫다고 판단했다.
대회 중
대회 중에는 일반 목적과 OpenClaw의 진입점으로 Cerebras/GPT-OSS-120B을 사용하고, 목적에 따라서 웹 검색에는 Gemini 계열을, 코드 작성 계열에는 GPT Codex 계열과 Claude를 사용했다. 답안 검증에는 최대한 다양한 모델을 사용하는 것이 목적이었기 때문에, 당초 계획상으로는 OpenClaw 편에 검증을 자동화할 생각이었다.
특히 구글 이미지 검색이 꼭 필요해보이는 문제가 있어서, 웹 검색에 Gemini를 사용하는 전략이 유효하구나 했던 기억이 있다. (하지만 이 문제는 환각 문제를 뒤처리하다가 제출을 하지 못했다..)
openclaw/PROMPTS/VALIDATE.md
Among the models registered with you now, use ‘poe/gemini-3-flash’, ‘poe/kimi-k2.5’, ‘poe/gpt-5.3-codex-spark’, ‘poe/qwen3.5-plus’, ‘poe/grock-4.1-fast-reasoning’, ‘cerebras/zai-glm-4.7’, and ‘cerebras/gpt-oss-120b’, respectively to verify the answers to the OOO questions. The requirements for the questions are written at ‘README.md ‘ and ‘REQUIREMENTS.md ‘, and the answers are at ‘ANSWERS.md ‘. Identify whether the written answers, their explanations, and grounds are valid. Whether the sentences/contents cited as grounds exist should be checked by reading the object directly. Write a summary table of the verification work (see t1) and detailed verification for each answer, and write a file called ‘VALIDATION_(modelname).mid’
t1: | Answer | Evaluation | Evidence | :-: | :-: | :– | | | | |
openclaw/PROMPTS/VALIDATE_KO.md
지금 너에게 등록된 모델 중
poe/gemini-3-flash,poe/kimi-k2.5,poe/gpt-5.3-codex-spark,poe/qwen3.5-plus,poe/grok-4.1-fast-reasoning,cerebras/zai-glm-4.7,cerebras/gpt-oss-120b을 각각 사용하여 문제 OOO의 답안을 검증하여라. 문제 요구사항은README.md,REQUIREMENTS.md에 작성되어있고, 답안은ANSWERS.md에 있다. 작성된 답안과 그 설명, 근거가 타당한지 파악하라. 근거로 인용된 문장/콘텐츠가 실재하는지는 직접 대상을 읽어들여 확인하여야 한다. 각 답안에 대한 검증 작업 요약표(t1참조)와, 상세 검증 내용을 작성,VALIDATION_(modelname).md파일을 작성하여라t1: | 답안 | 평가 | 근거 | | :-: | :-: | :– | | | | |
누구나 실제로 얻어맞기 전까지는 계획이 있는 법. 이날 따라 많은 것들이 의도대로 동작하지 않았다.
OpenClaw는 어떤 사고 과정을 거친 것인지, 본인이 동작하고 있는 기기의 로컬 git credential을 제거해버려 파일 공유 파이프라인이 완전히 무력화되었다. 심지어 이 문제를 파악한 건 대회 절반이 가까워졌을 때였다.
어떤 상황에서는, 에이전트 모드로 PDF 콘텐츠를 읽어들이도록 했더니, OCR 유틸인 테서렉트를 다운로드를 시도했다. 한술 더 떠, 로컬의 Vision 프레임워크를 사용하는 코드를 생성해내기도 했다. 이 건은 고속 출력을 위해 GPT-5.3-Codex-Spark를 사용한 것이 원인이 아니었나 싶다.
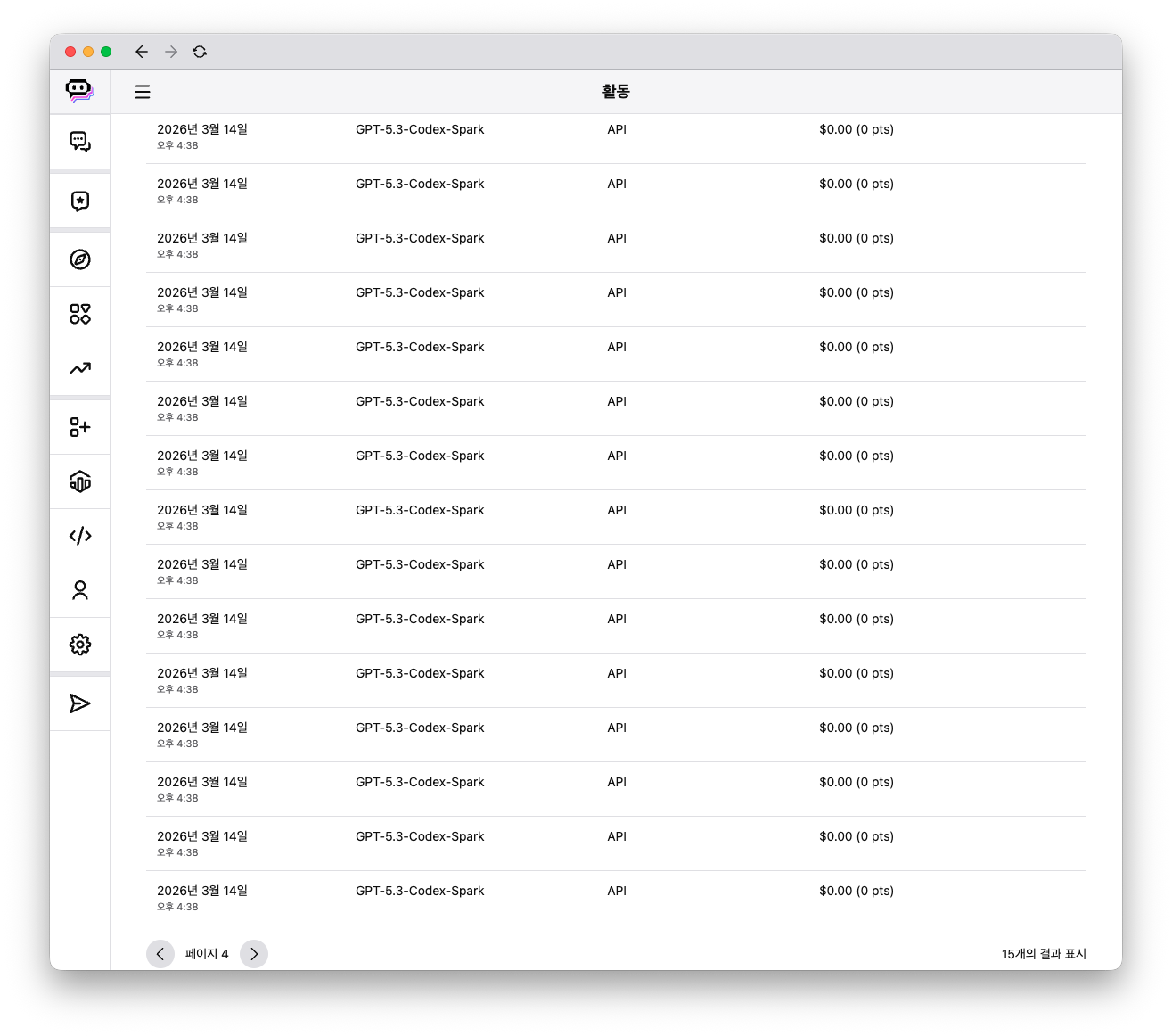
(참고) 0pts 부분은 입출력이 아무것도 이루어지지 않은 것이 아니라, 프로모션 때문인지 코스트가 0이어서 이렇게 되었다.
이윽고 OpenClaw는 특정한 모델을 사용하라는 명령을 모두 무시하고 Poe/GPT-5.3-Codex-Spark만 고집하는 상황에 이르렀다. OpenClaw 메모리에 특별한 지시 없으면 비용 최적화 모델을 사용하라는 프롬프트를 기록해 두었는데, 어떠한 이유로 모든 지시를 무시하고 비용이 0인 GPT-5.3-Codex-Spark 모델만 선택한 것으로 보인다.
문제 풀이 지시의 자동화 작업에 있어, OpenClaw는 가장 핵심의 역할이었다. 하지만 대회 중반부터는 더 이상 OpenClaw를 신뢰할 수 없게 되었다고 판단, 모든 지시를 직접 하는 것으로 바꾸었다.

때문에 100개의 항목에 대해서 무엇인가 확인해야 하는 작업이나, 각 답안에 대한 검증 명령 등을 직접 내려야만 하게 되었다.
이렇게 되니 내 타이핑 속도가 병목이 되어 결국에는 한 문제는 제 때 제출해내지 못하는 불상사가 벌어졌다.
마무리
결과: 제출 4/5 문제
이 대회를 준비하는데 있어, 프롬프트 준비도 미흡했고, 연습문제나 기출문제가 있는지 여부조차 확인해보지 않은데다, Star 찍어놓은 다른 프롬프트 사례집을 제대로 확인해보지도 않았다. 그래서 사실 불만족스러운 결과가 나온데 대해서는 할 말이 없다.
하지만 잘 되던 것이 갑자기 안 되어서 일어난 일들이 너무 많으니, 억울한 건 어쩔 수 없는 것 같다. 억울함을 풀기 위해서 대회가 끝나고도 한참의 시간 동안 분노의 디브리핑을 했는데, 그래도 뭐 내가 뭘 어떻게 할 수 있었나 싶기도 하다.
어째서 이런 일들이 벌어졌는지는, 이제부터 구체적으로 확인해나가야하지 않을까… 싶다.